

Evan Armstrong was a lead writer at Every who explored profit and power in technology in Napkin Math.
The AGI-in-2027 Thesis
Some researchers are convinced that we are on the cusp of superintelligence. Are they right?
Jun 13, 2024 · 10 min readUpdated Jul 15, 2026
Was this newsletter forwarded to you? Sign up to get it in your inbox.
There are two meaningful divides among technologists in AI. The first is that the technology is an iterative, genuinely useful improvement that will enable new use cases of software. AI is the next cloud, the next smartphone. I’ve covered this perspective extensively over the last few months with the latest Google, Microsoft, and Apple AI product roadmaps.
The other side is more…extreme. It believes that artificial intelligence will someday become artificial general intelligence (AGI) and, from there, self-improve to the point of being 10 times smarter than us. When that happens is debated. Whether that kills or empowers us is debated. How the technology will be able to self-improve is debated. But it is such a strong belief that every single AI research group has at least a few adherents.
Even if you, like most investors and founders today, dismiss the second scenario out of hand, it is worth considering its validity. Because the biggest companies in the world are acting like it is true. Elon Musk believes that we will have AGI in less than two years. Microsoft is drawing up plans for a $100 billion supercomputer to build models big enough for AGI that it intends to finish in about six years. The world’s most important AI companies—OpenAI, Google DeepMind, Anthropic—have AGI as the explicit mission of their organizations.
I’m covering this topic today because of this chart, pulled from a 165-page series of essays from Leopold Aschenbrenner, who was recently fired from OpenAI’s Superalignment research team. The series—entitled "Situational Awareness"—is his argument for why this second group is right and what we should do as a result.
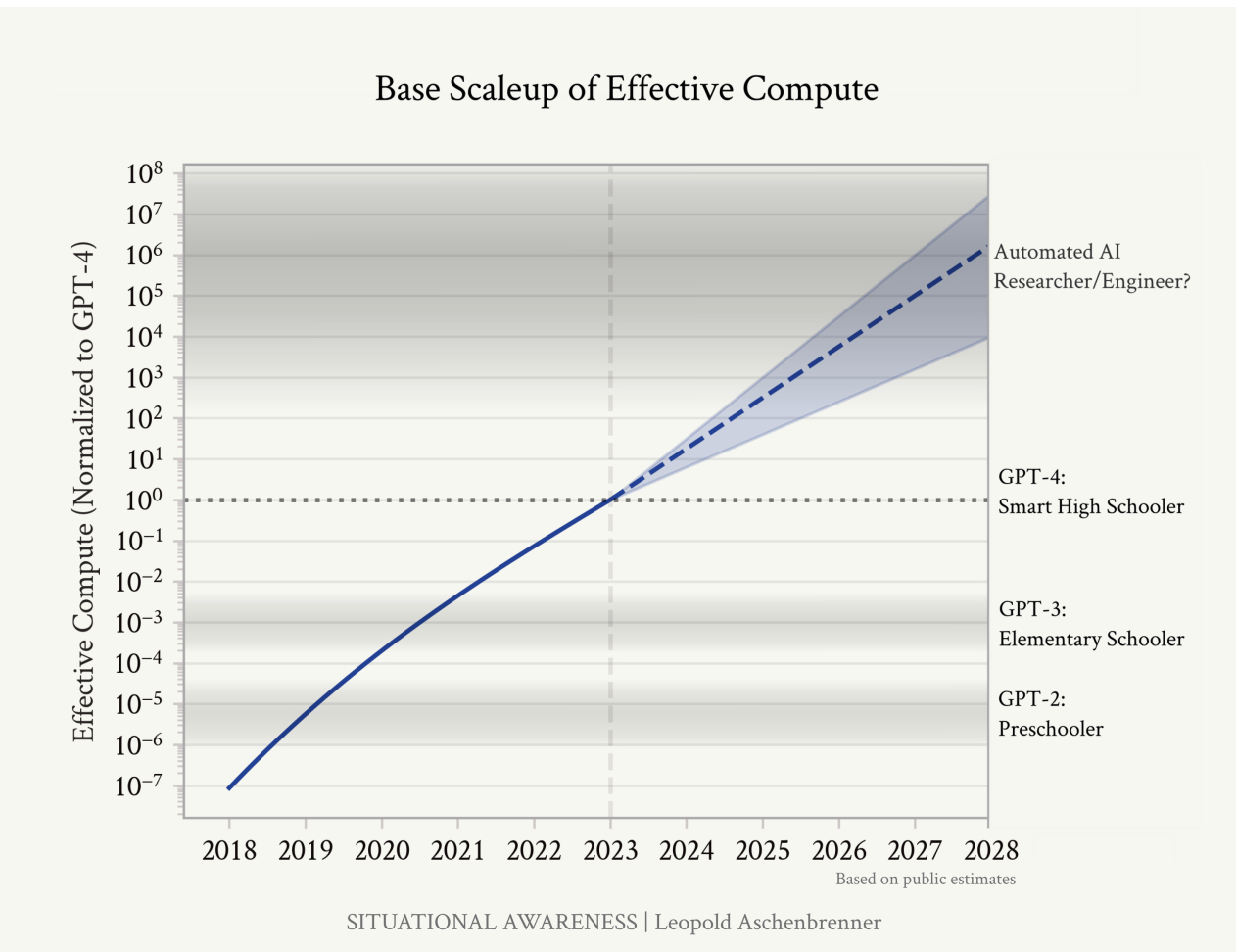
The basic thesis of this chart is this: Previous generations of LLMs have had forecastable logarithmic growth in their capabilities. Each time we increase the investment into training by 10x, we get a predictably large leap in LLMs’ capabilities. Aschebrenner believes that we are about two to three orders of magnitudes (OOM) of investment away from AI being able to conduct AI research, making it recursively self-improving. He says that it will be able to do so by making a “hundred million autonomous machine learning researchers.” Sure! Why not?
Aschenbrenner’s choice to publish these essays with a podcast interview and a bunch of Twitter threads is embedded with his own incentives. To me, this writing reads as a spurned lover trying to reclaim what was lost—his position of authority in the AI community after getting the boot from OpenAI. He is doubly incentivized to make a splash with them because he “recently founded an investment firm focused on AGI, with anchor investments from Patrick Collison, John Collison, Nat Friedman, and Daniel Gross.” (Online PDFs are a surprisingly effective way to raise interest in investment vehicles.)
He is so confident in his thesis that he threw the gauntlet at technology equity analysts like me, saying, “Virtually nobody is pricing in what's coming in AI.” First off, rude. Second, maybe he’s right. If superhuman intelligence really is about to be achieved in three years, maybe those five-year financial models I’ve been making are bunk. If nothing else, his writing is a useful framing tool to examine the AGI thesis. At its core, his argument is built on a series of three assumptions.
Become a paid subscriber to Every to learn about:
- The three key assumptions underpinning the AGI timeline
- Why "unhobbling" gains may not be so straightforward
- Why aggressive timelines require more than raw compute
- How AI leaders hedge bets with practical progress
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
















Comments