

Dan Shipper is the CEO and cofounder of Every. Every week he explores the frontiers of AI in his column, Chain of Thought, and on his podcast, ‘AI & I.’
A Few Things I Believe About AI
Taking time for a 10,000 foot perspective
Apr 21, 2023 · 10 min readUpdated Jul 7, 2026
CHATBOT COURSE EARLY BIRD PRICING ENDING SOON!
We are thrilled to announce we are relaunching our How to Build a Chatbot course! If you are interested in learning how to build with AI, join our upcoming Fall cohort taught by our very own Dan Shipper.
In the course you'll learn:
- How to aggregate sources of data for your chatbot
- How to manage your vector databases
- How to build a UI and bring your chatbot into production
- How to use Langchain and LlamaIndex to build a chatbot that can access private data, and use tools
- and so much more!
Learn how to build your own chatbot in less than 30 days. It will run once a week for five weeks starting September 5th and early bird pricing is available for $1,300 along with an Every membership. Last time we ran the course it sold out pretty quickly, so if you are interested, grab your seat now while early bird pricing still applies.
Early-bird pricing ends on July 31st, after that the price will be $2000.
Over the last 6 months I’ve been obsessively tinkering with, writing about, and investing in AI. It’s been a ride. I’ve talked to some of the most interesting thinkers in the space, I’ve stayed up late at night hacking zillions of little experiments, I’ve panicked about AI doom, I’ve imagined never organizing anything again, and I’ve basked in the warm glow of curiosity and delight I get from using these models.
Working in AI during this period has felt like having a SpaceX rocket strapped to my butt. I think everyone feels this way. You go very fast, but you constantly feel behind. Every once in a while your brain explodes with the possibilities in front of you. It’s easy to end up carried away with all caps tweets about how THE WORLD HAS CHANGED.
Today, I’d like to write something a little more nuanced and reflective. Even if you’ve got a rocket strapped to your butt, it’s important to look down every once in a while, and take stock of where you are. As such, here’s a short list of things I believe about AI that are shaping how I’m approaching my work at Every and beyond.
Knowledge orchestration is the most important bottleneck for AI applications
There are two important components to intelligence: reasoning and knowledge. GPT-4 is quite good at reasoning, but its knowledge of the world is limited. As such, its performance is bottlenecked by our ability to give it the right knowledge at the right time for it to reason with.
Unlock the power of AI and learn to create your personal AI chatbot in just 30 days with our cohort-based course. No advanced programming skills are required, just a desire to learn.
Here's what you'll learn:
- Master AI fundamentals like GPT-4, ChatGPT, vector databases, and LLM libraries
- Learn to build, code, and ship a versatile AI chatbot
- Enhance your writing, decision-making, and ideation with your AI assistant
What's included:
- Weekly live sessions and expert mentorship
- Access to our thriving AI community
- Hands-on projects and in-depth lessons
- Live Q&A sessions with industry experts
- A step-by-step roadmap to launch your AI assistant
Early bird pricing ends on July 31st. Sign up now to take advantage. Learn to build in AI—with AI in just 30 days!
This problem, which I’m calling knowledge orchestration, is the biggest unsolved problem for builders in AI outside of progress on foundational models. It touches how you store, index, and retrieve the knowledge you need to perform useful large language model tasks. There are many people trying to improve this at different layers of the stack:
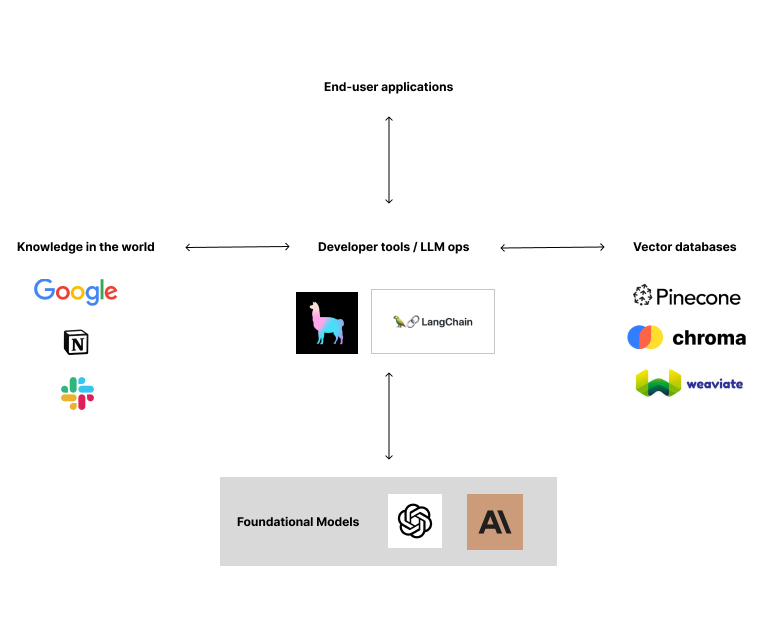
One layer up from that, LlamaIndex and Langchain are building at the developer tool / infrastructure layer. They’re making it easy for developers to chunk, store, and retrieve knowledge from various different kinds of databases with only a few lines of code.
Vector database providers are also working on this problem. Pinecone, Weaviate, and Chroma are all battling for supremacy here—with Pinecone in the lead.
Finally, various all-in-one solutions like Metal and Baseplate are bundling all of these layers of the stack together to make it easy for developers to get started. They’ve got slick web interfaces that make data observable, and easy for developers to get started quickly.
I suspect all of these players will start to leak out of their current layer of the stack, and try to grow into other areas. The right solution will figure out how to integrate layers in the right way to make it easy for builders to get started and to make iteration speeds faster.
Knowledge orchestration is the process around knowledge. But what about the knowledge itself? What kind of knowledge is most valuable?
Here’s one type that excites me:
LEARN TO BUILD A GPT-4 CHATBOT
Every is relaunching it's course on how to build your own chatbot in less than 30 days. It will run once a week for five weeks starting September 5th.
Early-bird pricing ends July 31st. The course is available for $1,300 along with an Every membership. Want to learn to build in AI?
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription options