

Dan Shipper is the CEO and cofounder of Every. Every week he explores the frontiers of AI in his column, Chain of Thought, and on his podcast, ‘AI & I.’
Linus Lee Is Living With AI
How a researcher uses generative AI to help him think better and get more done
Dec 3, 2022 · 12 min readUpdated Jul 7, 2026
Sponsored By: Tweet Hunter
This essay is brought to you by Tweet Hunter, the tool for growing your Twitter audience in just 5 minutes per day. Tweet Hunter helps you create high-performing content and turn those likes and replies into business results.
Chris Dixon is famous for writing, “What the smartest people do on the weekend is what everyone else will do during the week in 10 years.” If you want a glimpse of what you’ll be doing during the week in 10 years, you’ll find a lot of it on Linus Lee’s laptop.
Linus is an independent researcher focused on building better interfaces for people to interact with generative AI models. He wants to replace today’s prompt-based interfaces with affordances that provide greater predictability and control—things like pinch-to-zoom or drag-and-drop interactions for AI.
It’s important research, and his output is wildly prolific because his workflow is a loop. He researches generative AI, and uses what he discovers to build AI tools that will help him think better and get more done. He uses publicly available AI tools as well as a suite of custom-built models that help him read faster, search through information more quickly, and take better notes.
I originally noticed him because he kept dropping fascinating demos of research projects on Twitter. This one, for example, allows a user to make an example sentence longer or shorter by dragging it in different directions. Another one lets him easily explore style variations for Stable Diffusion prompts with just a click or two. A final one lets him visually explore changing a sentence across multiple dimensions—like increasing its positivity or its politeness.
Perhaps it’s this tight coupling that makes him such a good researcher. He’s both a user and a fan of these tools—and that gives him access to problems, and ways to solve them that others might miss.
Lee has granted us access to take a look at the suite of tools he uses to get his work done. Are you ready to peek at what it looks like to live with AI?
Let’s dive in.
Building an audience can be one of your greatest assets but it takes a lot of time and effort.
Introducing Tweet Hunter, the #1 tool to help you get results on Twitter while staying productive and focused on your day-to-day activities. Create better content and drive more opportunities from Twitter in just 5 minutes per day.
Here’s what you’ll be able to do with Tweet Hunter:
- Create a month’s worth of content in an hour
- Amplify your reach and engagement rate
- Identify new leads automatically
Join 3,000+ creators, founders, and consultants using Tweet Hunter to grow their businesses.
Try it free for a full week + enjoy a 30-day money-back guarantee.
Linus introduces himself
I'm an independent researcher focusing on building better interfaces for humans to interact with generative models. In particular, I’m interested in interfaces that allow for direct manipulation of text using latent space based language models. Basically, what that means is that I’m interested in exploring ways to use language models that look less like using prompts and more like familiar user interfaces like pinch-to-zoom or drag-and-drop.
Before becoming a researcher, I was your average React-TypeScript-wielding product engineer. But I always had a side hobby and interest in building knowledge tools to help people learn and read quickly and things like that. At the start of this year, I decided to take a year off from work to dive deeper into that question.
I spent the first half of the year looking at classic natural language processing (NLP) approaches to that question. Since May or June, I've been looking at more language model-based approaches.
How he does his research
I research generative AI, but I also use a lot of generative AI tools in my workflow. Some of those tools are ones I’ve built myself—I have an array of personal micro-tools that support what I do. I also use a few publicly available AI tools. The ones I want to share today break down into two big categories: tools for reading, and tools for personal knowledge management—like notes and search.
We’ll start with tools for reading.
Tools for reading
To find papers to read I use Elicit
A big part of research is figuring out what to read. It’s important to be able to do literature reviews and find papers that are relevant to the question you’re interested in.
Elicit is a literature review tool that uses language models to aid in people searching for what to read to answer a question. I might have a question like, “How does the depth of a transformer model affect its language modeling performance?” This is a fairly technical question, but it’s basically asking, “How does one part of the model’s structure affect its performance?”
Normally if I had this question I would Google something like, “language model depth paper.” Then I have to look at each link to figure out: does this answer the question? Who is it by? Is it a reputable paper? What are the results?
It’s a time-intensive process. But Elicit changes that. If I ask a question in Elicit, it churns on it for a little bit and then outputs a list of relevant papers:
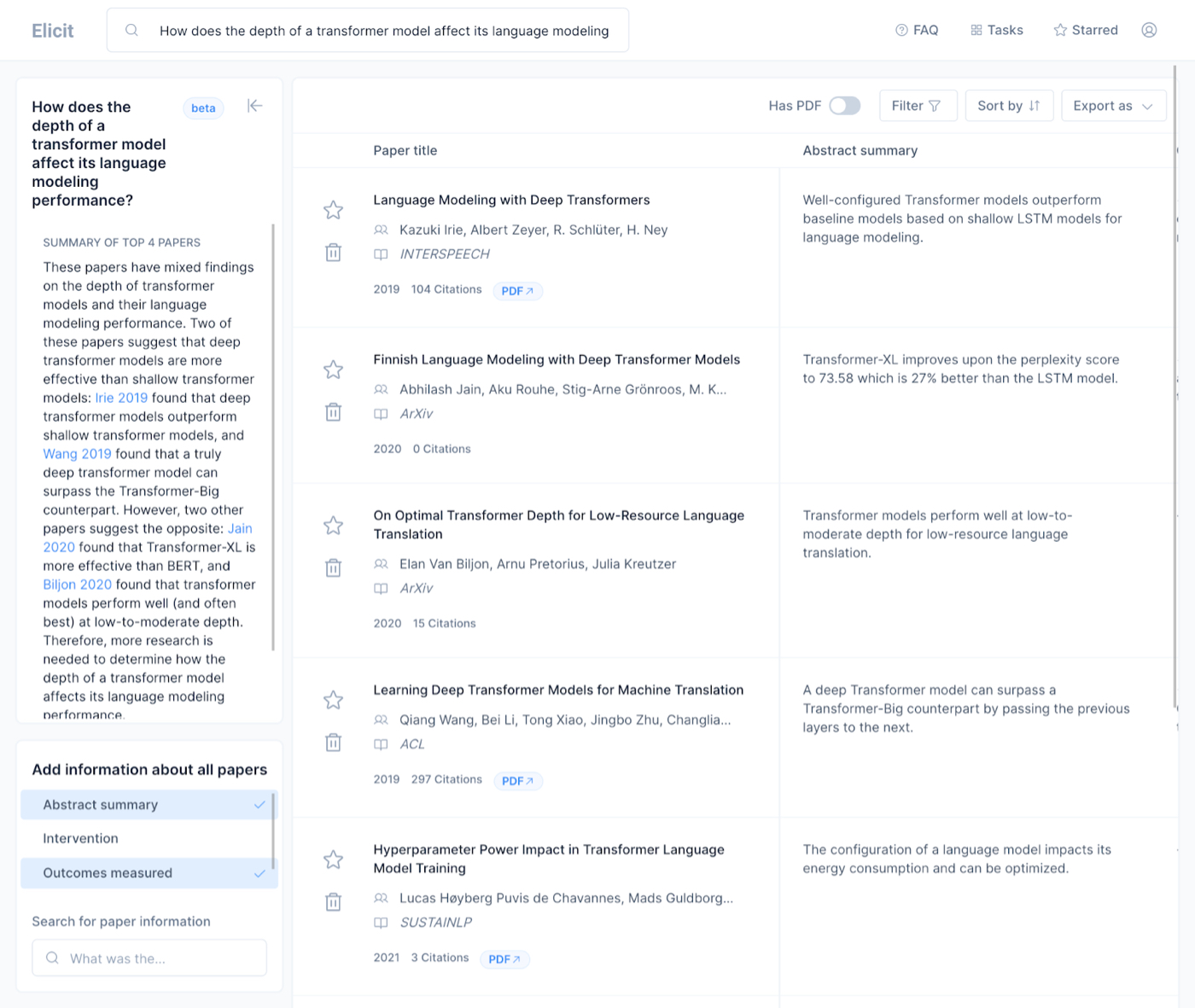
The papers it finds are great. it also outputs a summary of the abstract, so I can quickly tell if the paper is going to answer the question that I have. It has filters for things like the number of participants in the study or what the intervention was in the study, which is relevant for social science papers.
This is a good way to just discover new papers, especially because there are paper links that you see on Twitter, but they're so biased towards the last couple of months, and this gets you historical papers that you might have missed.
ExplainPaper helps me understand dense papers
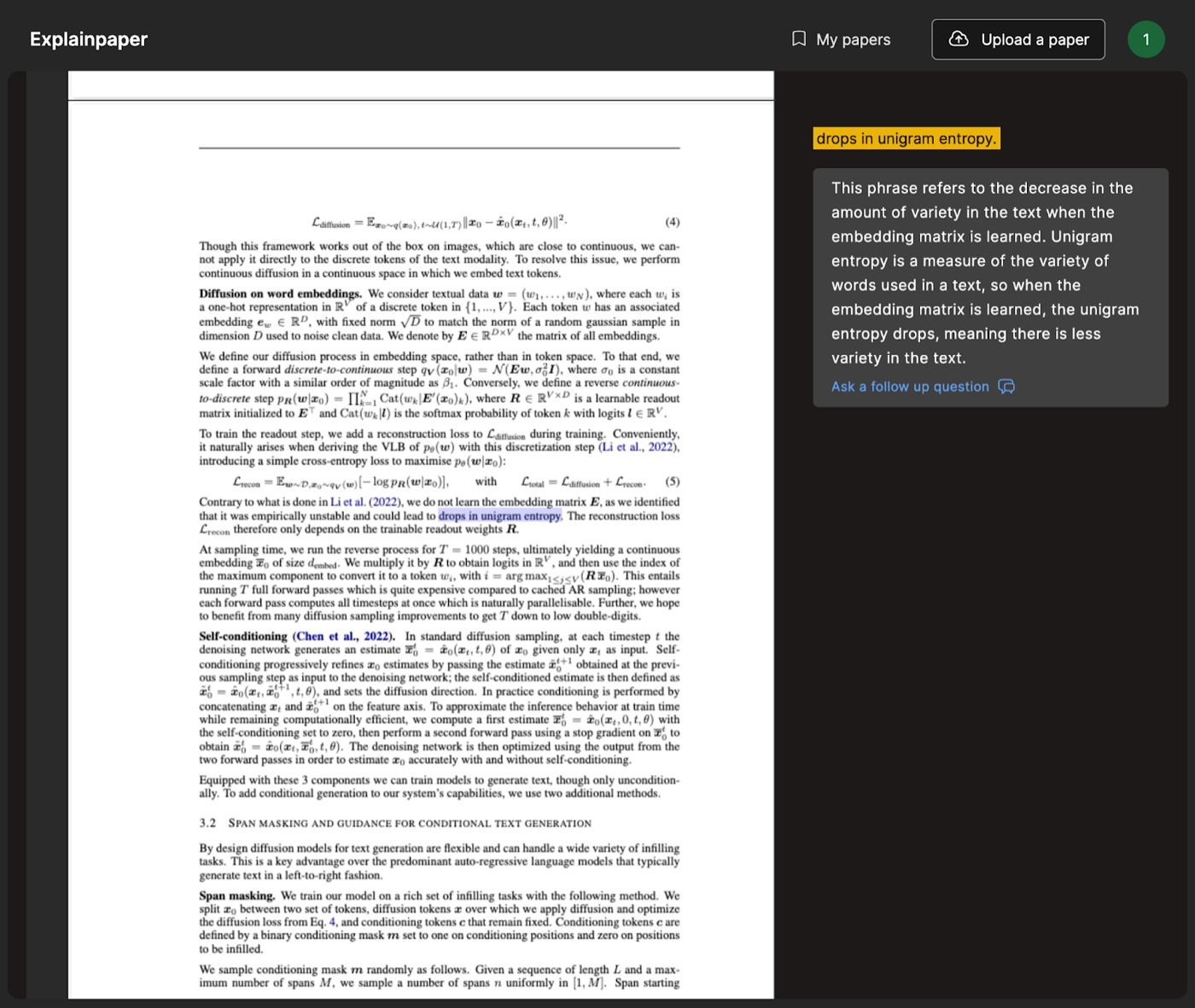
A new tool I’ve been using to help me read papers is called ExplainPaper. If you put in a paper, you can highlight any section of that paper and the tool will explain it to you.
This is useful for me because I don't come from a machine learning background, but I spend a lot of time reading papers to do the research I’m interested in.
Sometimes there are papers that are clearly written by engineers and other papers are clearly written by mathematicians. The ones that are written by mathematicians are just hard to wrap your mind around if you don't come from that world because they're a little bit too dense.
In ExplainPaper I can highlight a sentence that talks about an equation or a rule, and it will summarize and explain something that might be unclear:
I built a visual summarization tool for scanning through articles quickly
I read a lot, and sometimes I want to be able to get the most important parts of an article without having to read the whole thing. The obvious solution to this is a summarizer—but summaries have lots of limitations.
A summary is taking one wall of text and trying to get into a smaller wall of text. But you still have to scan through the summary. If you want to expand a specific point in the summary, you have to go back to the original text.
So, instead, I built a tool called CoStructure. It creates a visual heat map on top of an article to show me the most important sentences. So I can quickly jump to what’s most important without having to read the whole article.
I create the heatmaps with what’s called extractive summarization, which tries to identify sentences in the text that are most representative of the text as a whole by ranking every sentence in a text according to how many other sentences are similar to it. So if one sentence contains lots of topics that many other sentences mention, it ranks higher and is probably more central to the topic of the post.
Let’s say I’m reading an article and want to be able to skim through the most important points. I paste it into CoStructure like this:


Want to see the rest of Linus's setup, including his other custom AI tools and research projects? Subscribe!
Thanks to our Sponsor: Tweet Hunter
Thank you to this week’s sponsor, Tweet Hunter, the tool for driving audience growth in just 5 minutes per day.
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription options