

Dan Shipper is the CEO and cofounder of Every. Every week he explores the frontiers of AI in his column, Chain of Thought, and on his podcast, ‘AI & I.’
GPT-4 Is a Reasoning Engine
Reason is only as good as the information we give it
Mar 31, 2023 · 9 min readUpdated Jul 7, 2026
Sponsored By: Mindsera
This article is brought to you by Mindsera, an AI-powered journal that gives you personalized mentorship and feedback for improving your mindset, cognitive skills, mental health, and fitness.
In 1894, a Boston-based astronomer named Percivel Lowell found intelligent life on Mars.
Looking through a telescope from his private observatory he observed dark straight lines running across the Martian surface. He believed these lines to be evidence of canals built by an advanced but struggling alien civilization trying to tap water from the polar ice caps.
He spent years making intricate drawings of these lines, and his findings captured public imagination at the time. But you’ve never heard of him because he turned out to be dead wrong.
In the 1960s, NASA's Mariner missions captured high-resolution images of Mars, revealing that these "canals" were nothing more than an optical illusion caused by the distribution of craters on the planet's surface. With the low resolution available to his telescope at the time, these craters looked to Lowell like straight lines which, through a chain of reasoning, he theorized to be canals built by intelligent life.
Lowell’s story shows that there are at least two important components to thinking: reasoning and knowledge. Knowledge without reasoning is inert—you can’t do anything with it. But reasoning without knowledge can turn into compelling, confident fabrication.
Interestingly, this dichotomy isn’t limited to human cognition. It’s also a key thing that people fundamentally miss about AI:
Even though our AI models were trained by reading the whole internet, that training mostly enhances its reasoning abilities—not how much it knows. And so, the performance of today’s AI is constrained by its lack of knowledge.
I saw Sam Altman speak at a small Sequoia event in SF last week, and he emphasized this exact point: GPT models are actually reasoning engines not knowledge databases.
This is crucial to understand because it predicts that advances in the usefulness of AI will come from advances in its ability to access the right knowledge at the right time—not just from advances in its reasoning powers.
Mindsera structures your thinking with journaling templates based on useful frameworks and mental models, so you can make better decisions, solve complex problems, and be more productive.
Our innovative AI coaching helps you to achieve your goals by making mental models actionable. You get the power of a professional coach without paying over $250 per hour.
Mindsera smart analysis generates an original artwork based on your writing, measures your emotional state, reflects on your personality, and gives personalized suggestions to help you improve.
Build self-awareness, get clarity of thought, and succeed in an increasingly uncertain world.
Knowledge and reasoning in GPT models
Here’s an example to illustrate this point. GPT-4 is the most advanced model on the market today. Its reasoning capabilities are so good that it can get a 5 on the AP Bio exam. But if I ask it who I am it says the following:
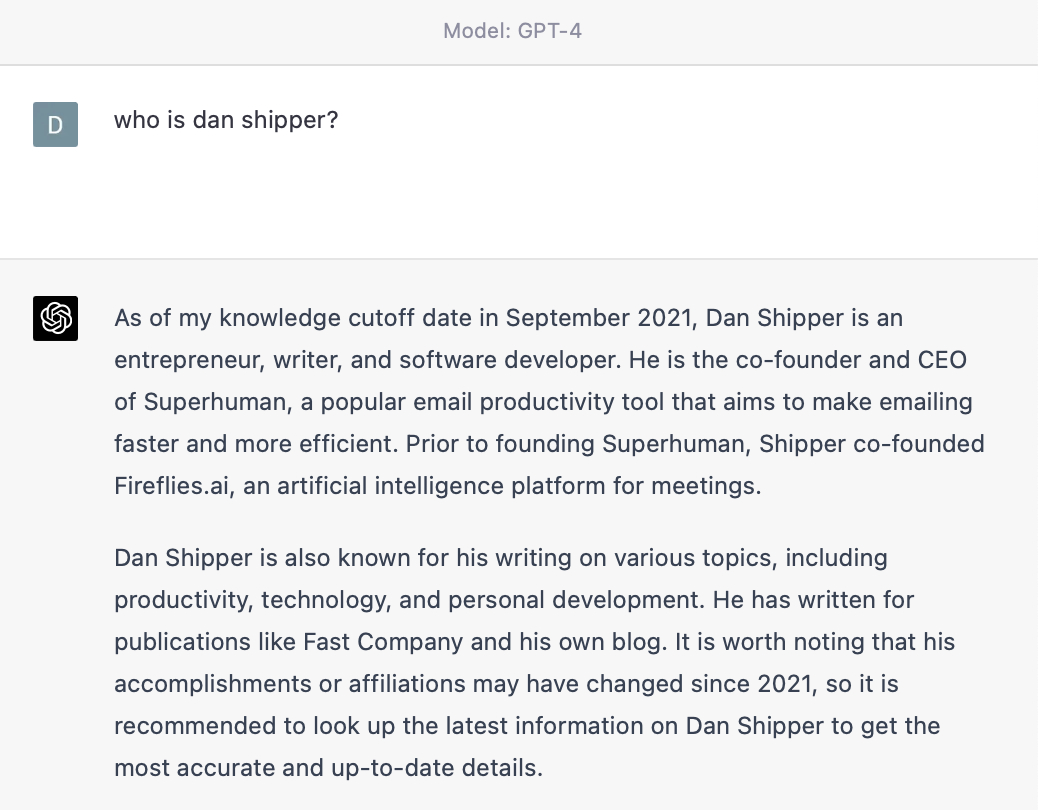
AI critics will be quick to say that this proves GPT-4 is nothing more than a stochastic parrot, and that its results should be dismissed offhand. But they’re wrong. Its performance improves dramatically the second it has access to the right information.
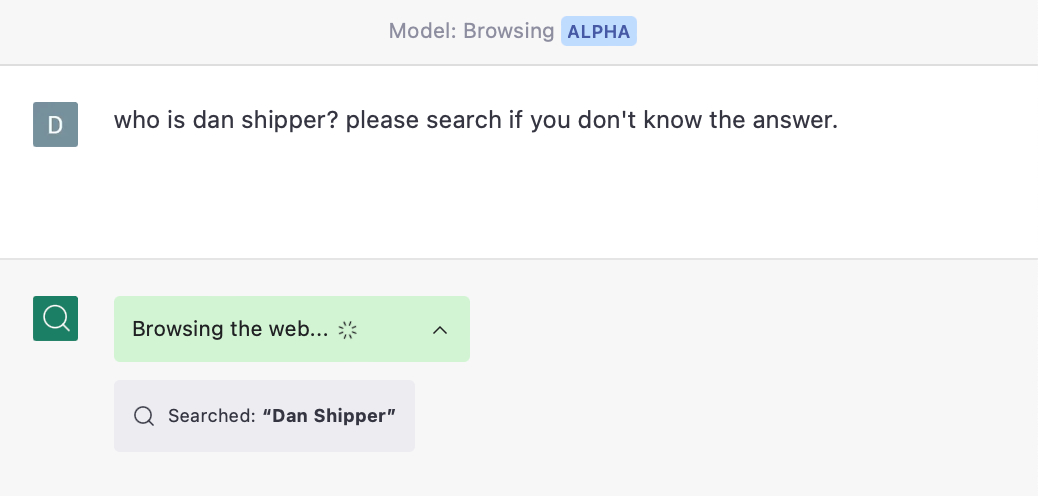
For example, I have access to a version of ChatGPT that can use web searches to ground its answers with what it finds on the internet.
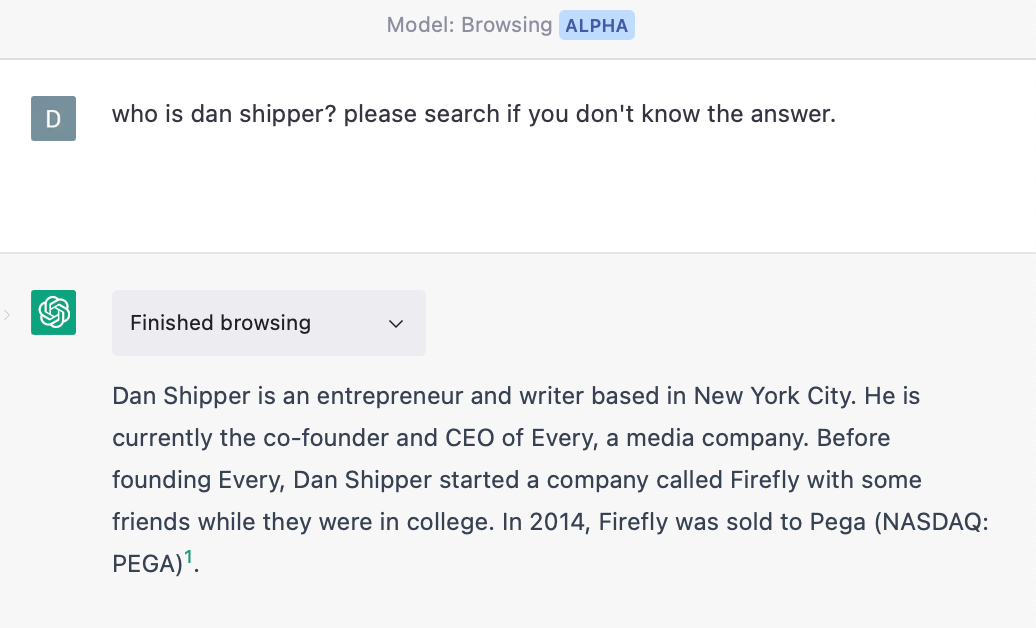
In other words, instead of using its reasoning capabilities to come up with a theoretically plausible answer, it does web research to create a knowledge base for itself. It then analyzes the collected information and distills a more accurate answer:
What’s going on here? GPT-4’s architecture is not public, but we can make some educated guesses based on previous models that have been released.
When GPT-4 was trained, it was fed a large portion of the available material on the internet. Training transformed that data into a statistical model that is very good at, given a string of words, knowing which words should follow from it—this is called next token prediction.
However, the kind of “knowledge” contained in this statistical model is fuzzy and inexplicit. The model doesn’t have any sort of long-term memory or way to look up the information it has seen—it only remembers what it encountered in its training set in the form of a statistical model.
When it encounters my name it uses this model to make an educated guess about who I am. It draws a conclusion that’s in the ballpark of being right, but is completely wrong in its details because it doesn’t have any explicit way to look up the answer.
But when GPT-4 is hooked up to the internet (or anything that acts like a database) it doesn’t have to rely on its fuzzy statistical understanding. Instead, it can retrieve explicit facts like, “Dan Shipper is the co-founder of Every” and use that to create its answer.
So, what does this mean for the future? I think there are at least two interesting conclusions:
- Knowledge databases are as important to AI progress as foundational models
- People who organize, store, and catalog their own thinking and reading will have a leg up in an AI-driven world. They can make those resources available to the model and use it to enhance the intelligence and relevance of its responses.
Let’s take these one at a time.
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription optionsThanks to our Sponsor: Mindsera
Thanks to our sponsor, Mindsera, an AI-powered journal that gives you personalized mentorship and feedback for improving your mindset, cognitive skills, mental health, and fitness.