

Dan Shipper is the CEO and cofounder of Every. Every week he explores the frontiers of AI in his column, Chain of Thought, and on his podcast, ‘AI & I.’
OpenAI’s New Model, Strawberry, Explained
ChatGPT’s next big evolution lies in its ability to solve the ‘strawberry’ problem
Aug 30, 2024 · 5 min readUpdated Jul 7, 2026
Was this newsletter forwarded to you? Sign up to get it in your inbox.
OpenAI has created a new model that could represent a major leap forward in its ability to reason. It’s called Strawberry. Here’s why:
If you ask ChatGPT how many “r”s are in the word “strawberry,” it famously fails miserably:
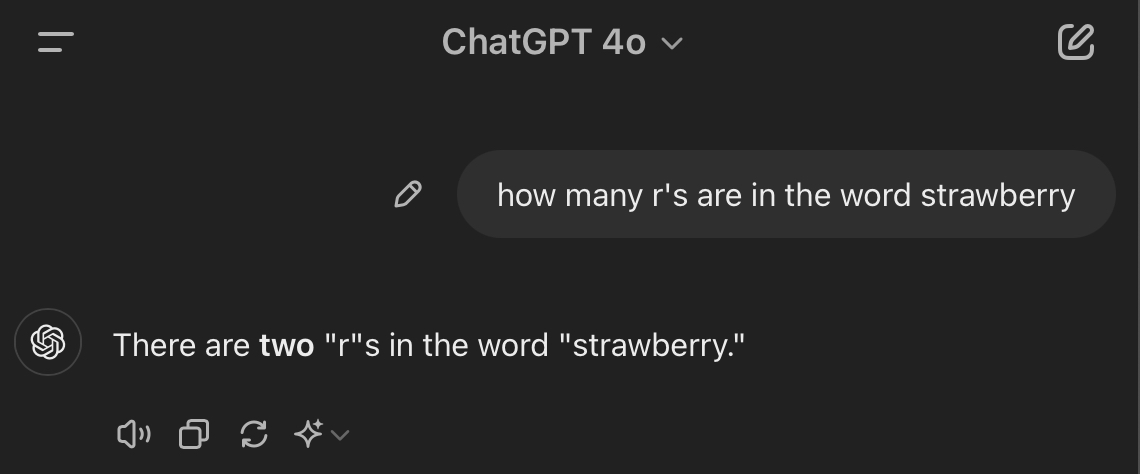
Become a paid subscriber to Every to unlock the rest of this piece and read about:
- Why ChatGPT struggles with letter counting
- The promise of process supervision
- The potential for true AI problem-solving
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription options