.png&w=3840&q=75)

Rhea Purohit focuses on research-driven storytelling in tech. She writes about the psychology and history of adopting new technologies.
Vibe Check: Gemini 3 Pro, A Reliable Workhorse With Surprising Flair
After 24 hours of hands-on testing, we found a model that’s fast, reliable, and surprisingly funny—but still prone to overreaching and not yet a writing champ
Nov 19, 2025 · 20 min readUpdated Jul 25, 2026
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Every got early access to Gemini 3 Pro—the brand-new model Google released yesterday—but the preview build wouldn’t quite work for our team. So we waited for the public release and have been testing it for the last 24 hours to get you a real feel for the model that’s become a workhorse for developers.
Our day-one verdict
Gemini 3 Pro is a solid, dependable upgrade with some genuinely impressive highs—especially in frontend user interface work and turning rough prompts into small, working apps. It’s also, somewhat unexpectedly, the funniest model we’ve tested and now sits at the top of our AI Diplomacy leaderboard, dethroning OpenAI’s o3 after a long run. But it still has blind spots: It can overreach when it gets too eager, struggles with complex logic sometimes, and hasn’t quite caught up to Anthropic on the writing front.
Let’s dive in.
What’s new?
Gemini 3 Pro: Google’s most advanced model to date is a natively multimodal reasoning model—meaning it can understand different types of input, like text, images, audio, or code, all in the same place without extra tools. It has a 1 million-token context window, on par with its predecessor Gemini 2.5 Pro. Back in the dark ages of May 2025, when Every’s engineering team was completely Cursor-pilled, Gemini 2.5 Pro was our model of choice inside the AI code editor thanks to its giant context window and sharp reasoning.
Google’s family of Pro models is built for deep, nuanced reasoning tasks, while its cheaper Flash models are optimized for speed, suited to low-cost, high-volume tasks. Google hasn’t launched Gemini 3 Flash yet, a release our team eagerly awaits.
Before yesterday’s launch, Gemini models had more than 13 million developers using them as part of their workflow. And according to Google CEO Sundar Pichai, Gemini 3 Pro is designed to reason more deeply, understand nuance, and infer the intent behind your request, so you can get what you need with less prompting.
Google Antigravity: An AI-powered independent developer environment (IDE) that combines a ChatGPT-style prompt window with a command-line interface pane and a built-in browser. (Command-line interface or CLI are the text-based tools developers use to type commands directly, rather than clicking around in a graphical editor.) But because our team does most of its work straight from the CLI (instead of in a full-fledged IDE), we didn’t test Antigravity as much—this Vibe Check focuses on Gemini 3 Pro, with a small section on Antigravity.
Let’s dig into where Every’s team thinks Gemini 3 Pro shines and stumbles, across coding, writing, and the set of benchmarks we’re nurturing inside Every.

Make your team AI‑native
Scattered tools slow teams down. Every Teams gives your whole organization full access to Every and our AI apps—Sparkle to organize files, Spiral to write well, Cora to manage email, and Monologue for smart dictation—plus our daily newsletter, subscriber‑only livestreams, Discord, and course discounts. One subscription to keep your company at the AI frontier. Trusted by 200+ AI-native companies—including The Browser Company, Portola, and Stainless.
The Reach Test
Dan Shipper, the multi-threaded CEO 🟨
I’m not clearly reaching for Gemini 3 Pro for anything but I’ll be experimenting more with it. There’s obviously a lot of capability there to unlock.
Kieran Klaassen, general manager of Cora
The Rails-pilled master of Claude Code 🟩
I’m very curious to keep using it more, and also, I want Gemini Flash 3.
Danny Aziz, general manager of Spiral
The multi-model polyglot 🟨
It seems to be pretty decent at user interface, and when there is a proper plan—it will go and implement the whole [thing]. But for fixing bugs, exploring, and prototyping [quickly trying out rough versions of an idea] where I don’t really know what the hell it is that I’m looking for, I find Sonnet to be a much better model for this kind of stuff.
Andrey Galko, engineering lead
The cautious vibe coder 🟩
I don’t think it’s an immense step for code generation, but it’s a solid step forward in quality and reliability… It nails complicated things from one go, and most things work well right away. It’s a big step forward for user interface work: It’s much more creative, and it has more variability and chaos (in a good sense) in its output.
Alex Duffy, cofounder and CEO of Good Start Labs
He who makes AI agents fight each other 🟩
Gemini 3 is a step change and improvement that I haven’t felt since Claude 3.5 Sonnet’s release. It’s noticeably better at most things besides writing that I’ve tried it on. I’ll maintain use of Claude and ChatGPT for coding but I’ll use a lot more Antigravity and Gemini, if Google’s rate limits will allow it. This Google stan continues to be a happy Google stan.
Naveen Naidu, general manager of Monologue
Graduate of IIT Bombay (the MIT of India 💅)
🟩 For frontend/UI work: Gemini 3 Pro is my new go-to. It strikes the perfect balance between quality and prompt adherence. Where Claude over-engineers and Codex underwhelms, Gemini 3 Pro hits the sweet spot.
🟨 For complex logic: I still reach for Codex 5.1 when I’m building features that require careful reasoning, handling edge cases, or working with complex state management [ keeping track of changing information in the app, like what screen the user is on]. Codex’s precision is unmatched.
My ideal workflow is using Gemini 3 Pro to scaffold UI [create a basic skeleton of the app’s interface] and create frontend components [ the building blocks of what users see and interact with], then switch to Codex 5.1 when implementing complex logic or debugging intricate issues.
Using it for coding
Where Gemini 3 Pro shines
It’s precise, reliable, and does exactly what you need it to
Putting it through its paces for real iOS development
Naveen tested Gemini 3 Pro in Factory’s CLI Droid by asking it to help build new features for the iOS app for Monologue, Every’s voice dictation app. He started by having the model add database features—essentially teaching the app how to save and retrieve information—using a library, which is a pre-made bundle of code developers use so they don’t have to build everything from scratch.
The twist was that he chose a niche SQLite library from a company called Point-Free. SQLite is a lightweight, built-in database that apps use to store information on your device, and since this one is so new, it probably wasn’t in Gemini’s training data. That made it a great test of whether the model could read the documentation, learn the library’s unique rules, and use it correctly inside his existing codebase.
He was impressed by how strong Gemini’s initial setup was. “It not only configured everything correctly,” he says, “but it also analyzed my codebase on its own and added a sample table that matched my schema [or a blueprint for how information is organized in the database]—without me even asking.” The code it produced was clean and well-structured, and showed how well the model could adapt to a library it hadn’t seen before.
Three frontier models go head-to-head to redesign an app
To test Gemini 3 Pro, Kieran (the general manager of Cora) pitted it against Anthropic’s Sonnet 4.5, OpenAI’s GPT-5.1, and Cursor’s Composer 1 Alpha, asking each to improve the design of an “ugly-looking” app—his words, not ours—that he’d vibe coded with Sonnet 3.5 a year ago.
The TL;DR is that Kieran sees Gemini 3 Pro as a reliable, workhorse model, good for routine tasks and tooling, where predictability matters. It’s consistent, careful, and clearly trained to avoid mistakes, but that caution makes it less creative than Anthropic’s models. “Google is more about models that just work,” he says. We’ve documented Kieran’s process below for more details on the specifics of the test he gave the models and how each one fared.
This is a screenshot of the vibe coded app in all its original, unpolished glory:
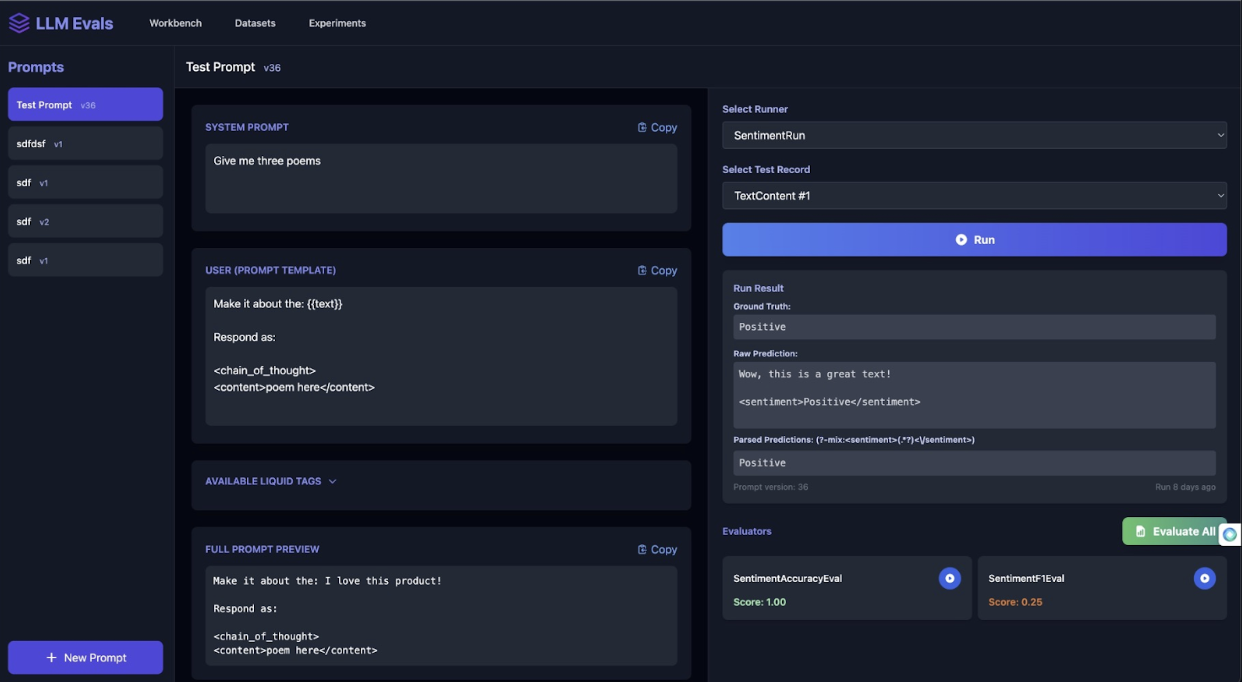
Below is a screenshot of a prompt Kieran Monologue-d into Cursor asking the models to create a design system (a design system refers to the set of visual components and rules that define how the app should look and behave):
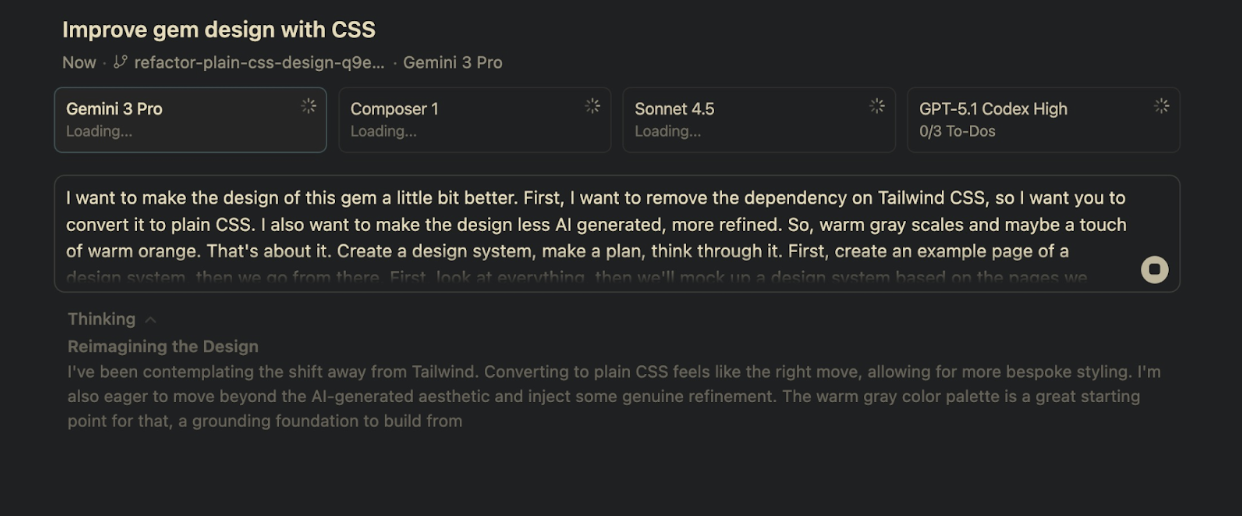
Gemini 3 Pro
Gemini 3 Pro wobbled right out of the gate. Kieran asked it to start with a simple HTML example file—basically a tiny starter page, the bare minimum you’d build to show what an app looks like. Instead, the model skipped over that step and began implementing the design system.
This is a screenshot of what the overeager Gemini 3 Pro generated:
Kieran wasn’t thrilled with Gemini 3 Pro’s first attempt. It didn’t follow his instructions to build a proper design system, and even in its overeager effort, it failed to recreate all the components on the page. “Also it’s the only [model] that didn’t do dark mode,” he says.
He prompted the model to recreate one of the components it had initially missed, which the model diligently handled. Even though he’d been originally looking for a design system, Kieran notes that Gemini 3 Pro was “very consistent” and “hit all elements” on the page.
Here’s Gemini 3 Pro’s second go at the redesign:
After some back-and-forth—mostly Kieran asking it to use all the elements from the actual page of the vibe coded app he was trying to redesign, and to hold off on implementing anything until it had shown a clean mockup—these are a couple of screenshots of the final design system by Gemini 3 Pro. Kieran appreciates its consistency and precision, but says it doesn’t really spark anything for him. “It just does the job,” he says—and, as the Claude stan he is, adds—“which is not bad, but it feels different from Anthropic’s models.”
Sonnet 4.5
Kieran felt that Sonnet 4.5’s design system bore too many marks of being vibe coded—the color, copy, and gradient felt a little “cookie-cutter AI”—but overall it was solid. Here’s a screenshot of the same:
Composer 1 Alpha
Kieran preferred Composer’s attempt to Gemini 3 Pro because it followed his instructions exactly—it created the design system without rushing ahead to implement it—and worked much faster. He also liked it more than Sonnet 4.5, because it didn’t have that familiar “cookie-cutter AI” smell he’s unusually sensitive to in Anthropic models (and may have been trying to get away from this time). This is a screenshot of Composer’s attempt:
GPT-5.1
GPT-5.1 tripped over the same issue as Gemini 3 Pro, rushing ahead to implement the design system instead of pacing itself. Kieran appreciated that GPT 5.1 generated something that looked a little different from the other two models, but ultimately he didn’t think the aesthetics were great. Here’s a look at the same:
The model is an ace at frontend and UI development
Three LLMs walk into a bar and try to one-shot an iOS app
Naveen asked Gemini 3 Pro, GPT-5.1, and Claude 4.5...
Become a paid subscriber to Every to unlock this piece and learn about:
• Why Gemini 3 Pro betrays its allies 89% less than its predecessor—and what changed
• The one coding task only two models can execute—and Gemini just joined that club
- • How a two-word prompt broke AI’s predictable design patterns—and dethroned Claude
Thanks to our Sponsor:

Make your team AI‑native
Scattered tools slow teams down. Every Teams gives your whole organization full access to Every and our AI apps—Sparkle to organize files, Spiral to write well, Cora to manage email, and Monologue for smart dictation—plus our daily newsletter, subscriber‑only livestreams, Discord, and course discounts. One subscription to keep your company at the AI frontier. Trusted by 200+ AI-native companies—including The Browser Company, Portola, and Stainless.
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription options