
In Michael Taylor’s latest piece for Also True for Humans, his column about managing AIs like you'd manage people, he delves into using AI agents for synthetic market research—specifically, he generates AI personas for multiple Hacker News users based on the comments in their profiles. Michael applies the wisdom of the crowd concept to working with AI to determine how agent-based simulations can help us make better business decisions. If you want to try our Hacker News simulator to test your own headlines, join the waitlist at askrally.com.—Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Imagine walking into that sales meeting for the 50th time (the first 49 were virtual), ready to handle every objection. Or sending that marketing email to 100 AIs first, to catch any mistakes before you roll it out to your 100,000-person email list.
Whether it’s your advertising, website copy, or social posts, there are real-world consequences to getting your messaging wrong. Why not practice on an AI audience first?
Large language models are unusually good at roleplaying, and if you string enough of them together, you can simulate how the market would react to your business idea, potentially mitigating some of the risk. Instead of talking solely to ChatGPT, you can chat with many GPTs at once, each with a different persona that matches the target audience you’re trying to reach. Pitch your startup to this virtual crowd, and get hundreds or thousands of responses that simulate what would happen in the real world. Since AIs never get tired of you asking, you can run every question by your AI audience and keep iterating on your idea until you’re sure you’ve got something good. Then, you can roll it out to the real world.
I recently explored this idea as a prompting technique I call "personas of thought," but I wanted to see how far we could take this concept to simulate a real-world scenario: testing link headlines on Hacker News. I’ll share how I tested different ideas while building Rally, a synthetic market research tool, going head-to-head with AI agents roleplaying as Hacker News users. And I'll show you a technique for getting AI to stop being polite—and start giving you the brutal feedback that makes your ideas better.
ChatGPT versus multiple GPTs
ChatGPT responses are the average of all the internet, because that’s what the underlying AI models were trained on. After training, engineers fine-tuned the models to make them prioritize helpful responses as judged by human feedback. This is what makes ChatGPT such a useful assistant, but it can be hard to get out of it a real, honest opinion like you might from a human colleague.

In this screenshot of ChatGPT, I asked it to compare the (controversial) new slogan for iconic British luxury car company Jaguar, “Copy Nothing,” against its traditional tagline, “Grace, Pace, Space.” The response is a perfect example of how ChatGPT defaults to writing like a marketing textbook instead of responding with a human opinion.
Because ChatGPT has ingested much of the internet in its training data, it has seen how a wide variety of individual people speak, and it can roleplay them with remarkable accuracy. Even with a small amount of direction, you can elicit noticeable differences in the responses.
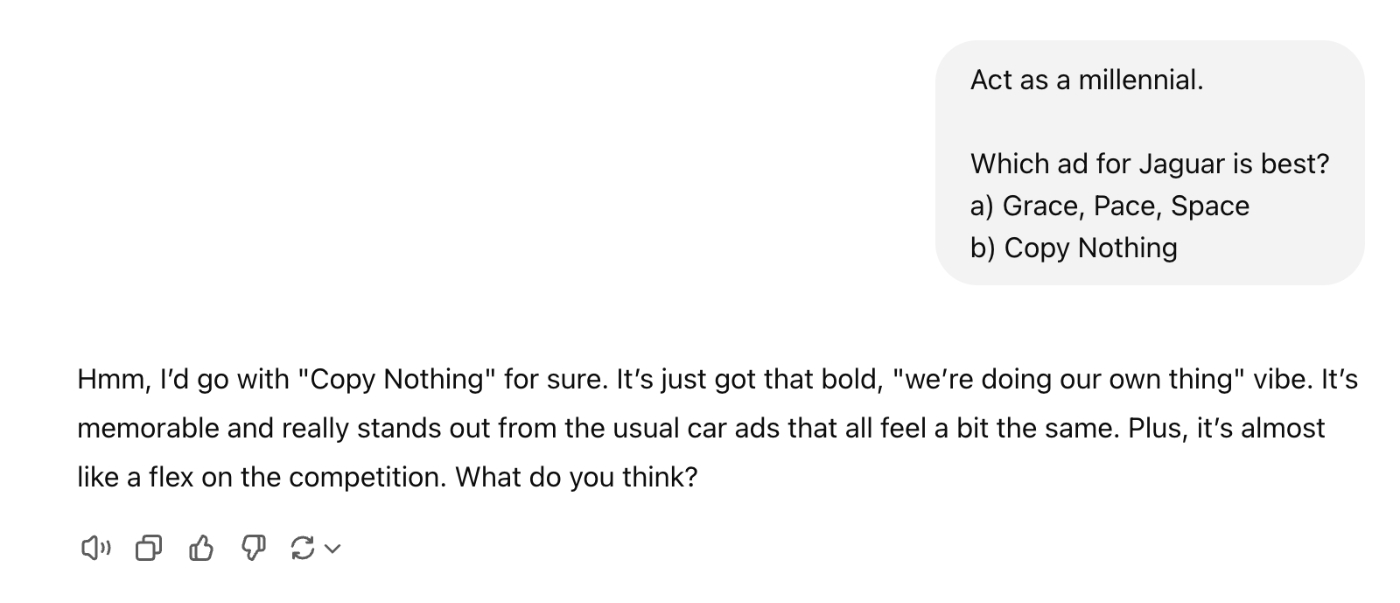
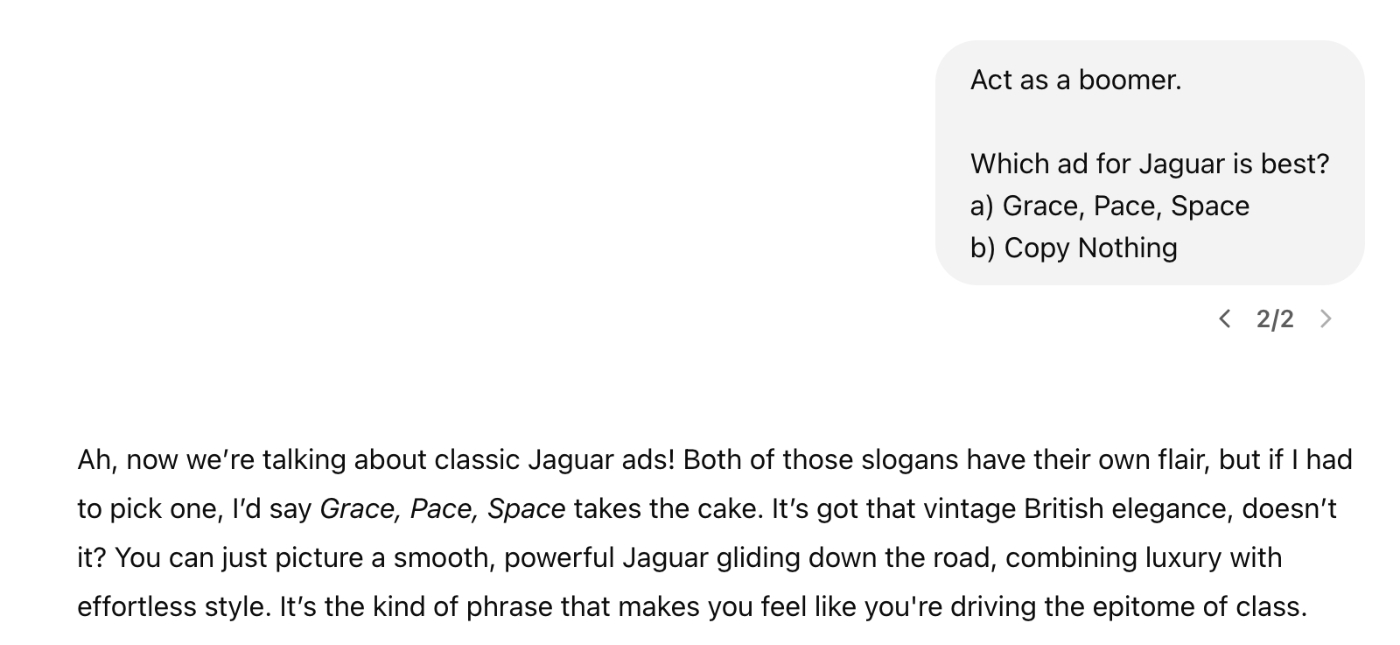
Given a more detailed persona based on a two-hour interview with a human, ChatGPT can replicate their answers on surveys with as much as 85 percent accuracy. The recent introduction of so-called reasoning models like OpenAI’s o1 and Deepseek’s R1 (baking the chain of thought prompting technique directly within) showed how powerful it can be to get the model to think through a problem before answering. Much like how chain of thought decision-making helps a model answer logical problems with LLMs, personas of thought are key to solving creative problems with LLMs. It’s a leap from step-by-step thinking to person-by-person thinking.
Market research with synthetic people
I started building Rally at the beginning of the year to give myself an interface for running these "personas of thought"-type of queries. Normally I would need to copy and paste the question “Which ad is best?” between ChatGPT sessions for each individual AI persona. With Rally, I can send a prompt to more than 100 AI agents at once, and it aggregates their responses. When I ask for feedback on the Jaguar advertising copy, I get a diversity of opinions from different personas instead of the average, fairly dull ChatGPT response. When I’m testing headlines, I can see which one my audience picked most often, learn why, and decide whether I need to further refine what I’ve written.
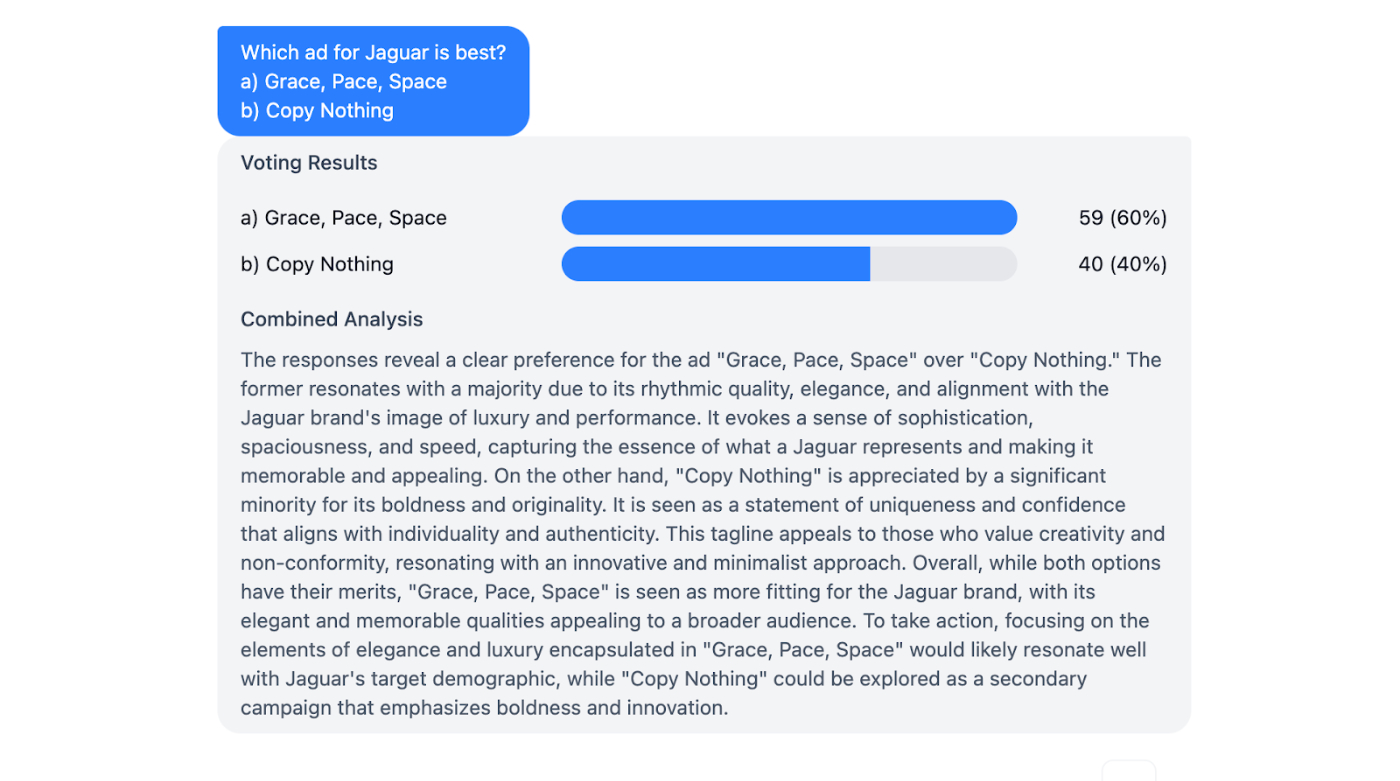
And by digging into individual responses, I can see which personas voted for which copy and skim the reasons why. About 40 people are currently testing the tool, and the most common feedback is that seeing the responses from individual AI personas often changes their minds about what their audience would like in real life. It’s like an A/B test, but faster and cheap enough to run every idea past your audience—ideas that you wouldn’t spend the time and money testing in real-life market research, because the cost and time commitments necessitate only bringing your best and most polished ideas to human beings.
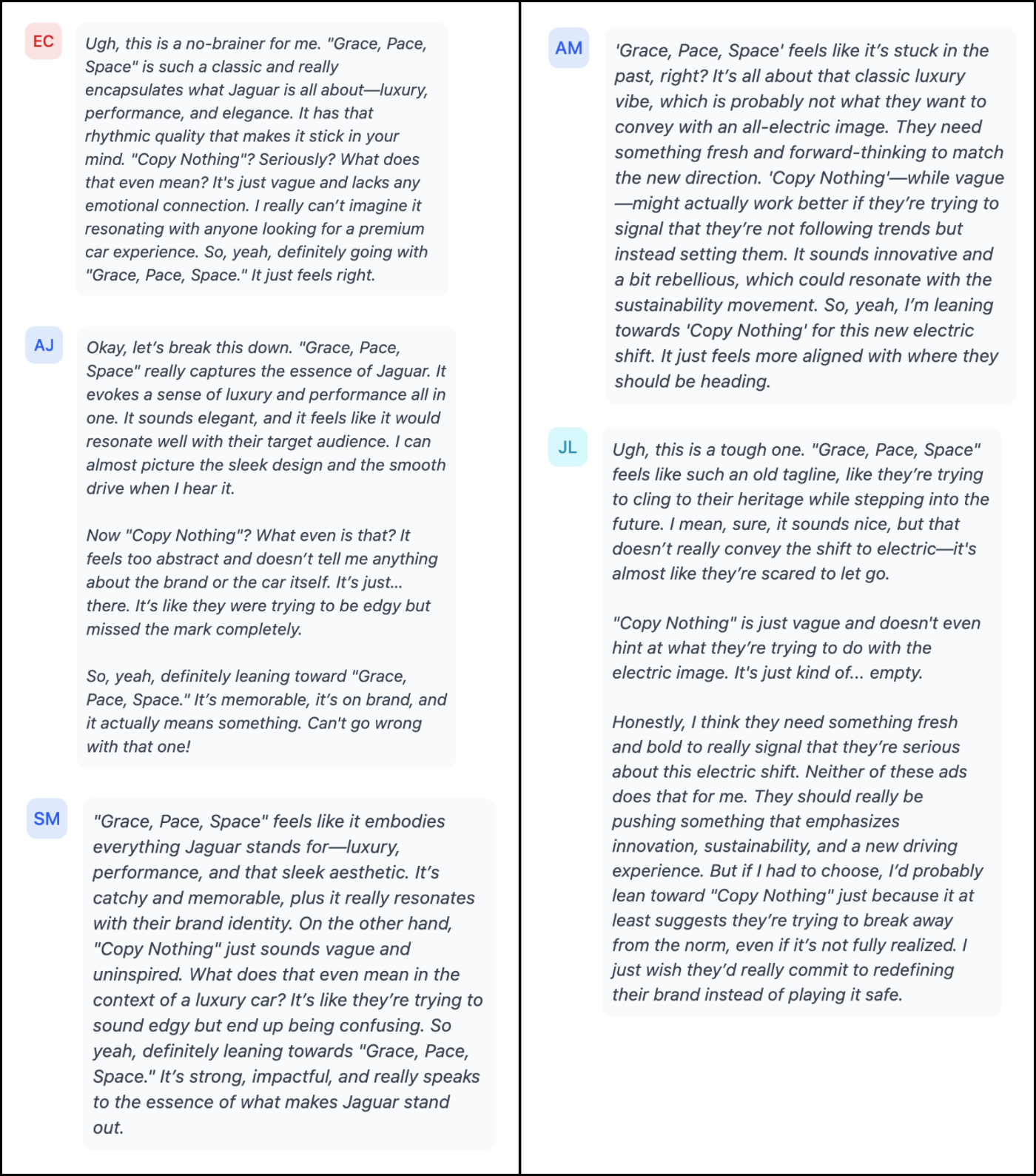
Source: Rally. Courtesy of the author.
In my own work as a prompt engineer, AIs make excellent judges, even when their own AI-generated ideas aren’t that creative. It makes sense: It’s easier to be a critic than to create. Theodore Roosevelt may have said, “It’s not the critic who counts,” but it’s helpful as the man (or robot) in the arena to seek feedback on how you can improve. The results only need to be directionally correct to be useful, because reading the reasons for which the agents said they liked (or hated) an idea helped me make up my own mind.
‘I want a Hacker News simulator’
Every CEO Dan Shipper is one of the 40 people beta-testing Rally, with the most common use cases being gauging effective article headlines, gathering feedback on pieces before they’re published, and even serving as the tie-breaker between team members when they disagree on creative direction. Trending on Hacker News can bring tens of thousands of people to Every’s website, so Dan had the idea of using Rally to A/B test Every headlines on an audience that mimics the real Hacker News audience.
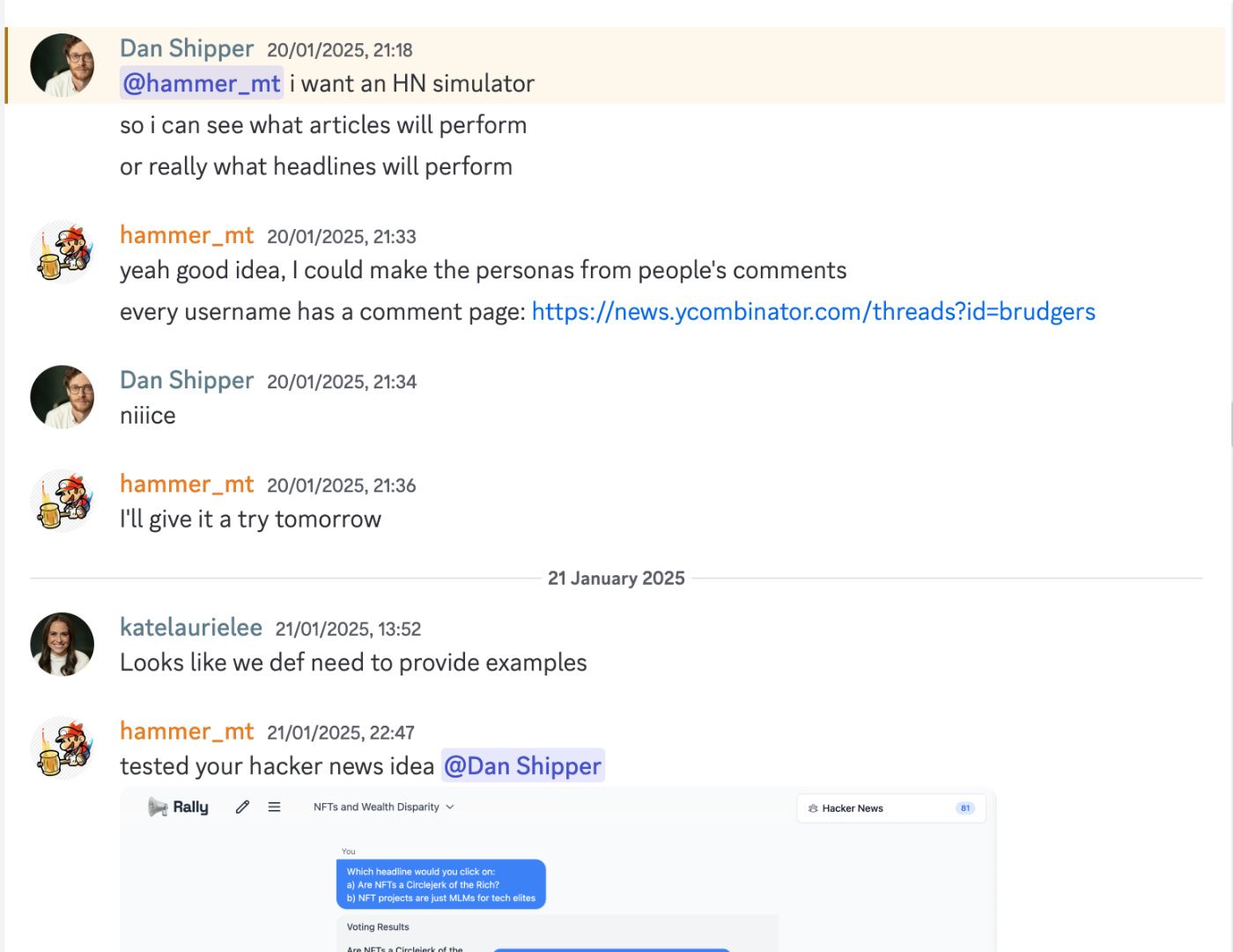
Mad Men-era marketer David Ogilvy estimated that five times as many people read a headline as the article itself. Even small changes to the headline can boost your chances of going viral, to which the results attest. AI coding tools like Cursor make it quite easy to write custom software, so I wrote a script that scraped the comment history from the profiles of 81 Hacker News users who had commented on the first few stories that day in order to build relevant personas for each of the profiles of people who had commented. Then I fed this audience into Rally and ran queries against this virtual Hacker News audience.
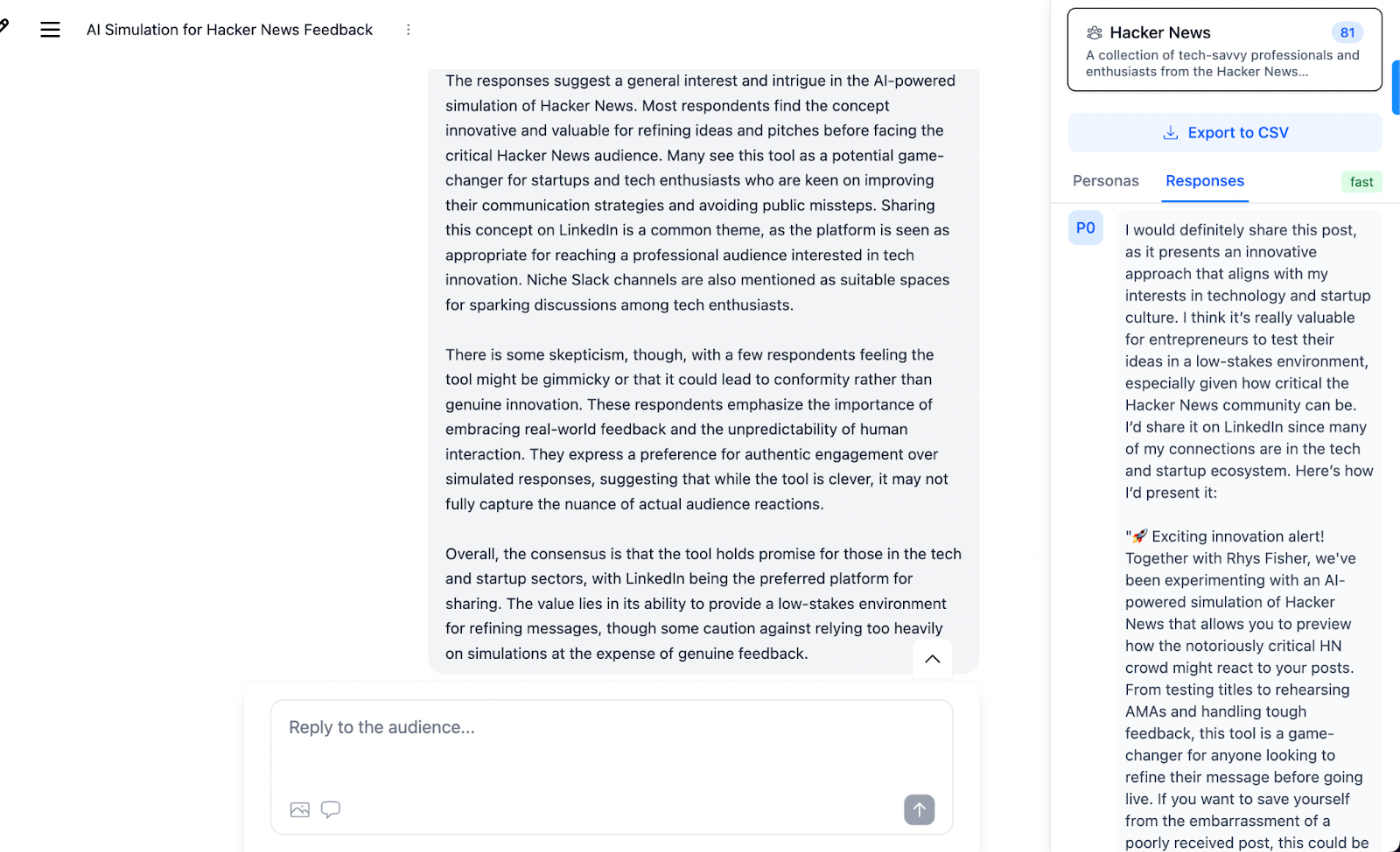
Most people don’t realize that when they leave comments on social media or online message boards like Hacker News, they talk a lot about themselves. They might mention where they live, what job they do, or what their interests are. All of this information can be extracted by an LLM and turned into a user profile with the following instructions: “Create a persona with a relevant background, demographics, and experience based on your best inference from the sample data provided.” The result is shockingly good: In the below example, this person didn’t even mention their name, but they did say in comments that they lived in Austin, Texas, grew up in Pennsylvania, studied computer science in Carnegie Mellon University, and love Mozilla Firefox. The name and income is made up by an LLM, but the profile is consistent with all the personal details this user posted.

Asking LLMs which of our headlines they liked was useful, but our headlines won’t be the only ones on Hacker News that day: Whether someone clicks on your headline or not depends greatly on how interesting the other stories are. LLMs tend to be too nice to you, telling you your ideas are great. To see if our headlines were competitive, we needed to go head-to-head against actual Hacker News headlines without the AI personas knowing which headline was ours. We wrote a script that pulled in the top trending stories on Hacker News so we’d have something realistic to compete against.
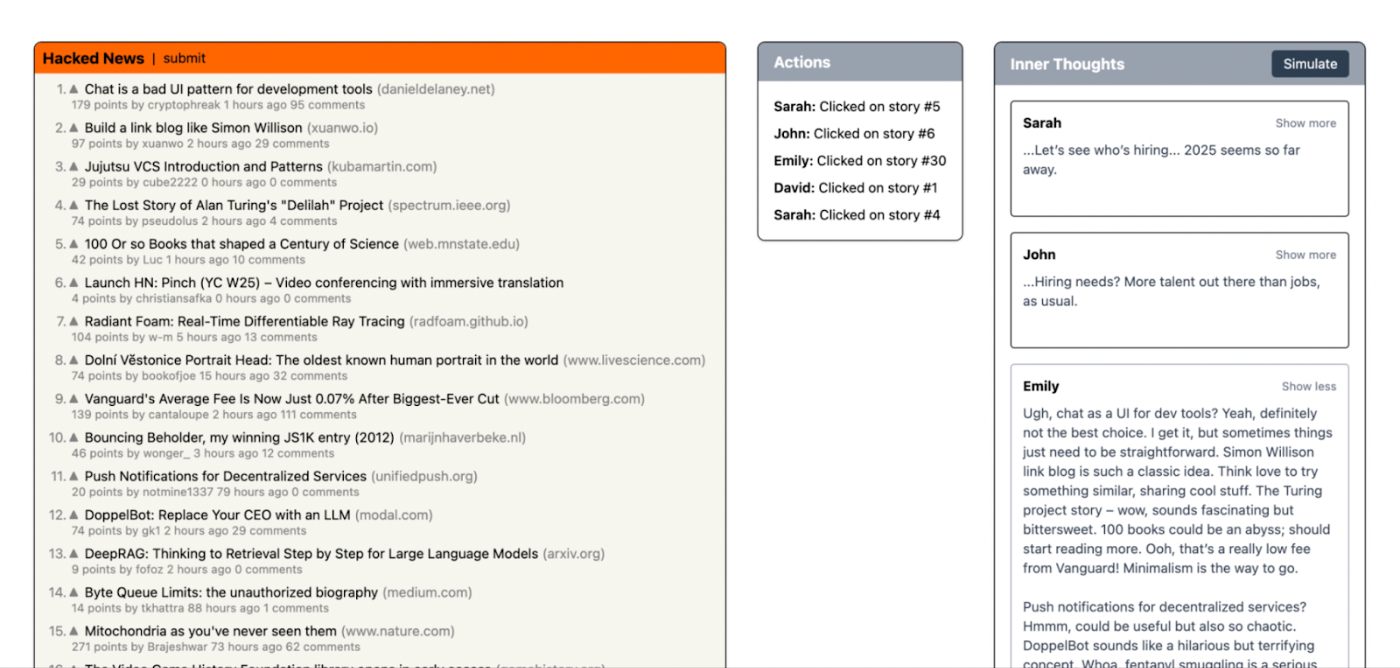
Once everything was hooked up in Rally, I got my 81-person Hacker News audience to work, deciding which headlines to click and explaining to me why. One of the first ones I tested was for this very article. I tried a number of different headlines, inserted amongst the real Hacker News headlines (without the AI personas knowing which was ours), including:
- “I created a HN audience simulator to doubt myself sooner”
- “I simulated HN trolls—now my wife thinks I spend too much time arguing with them”
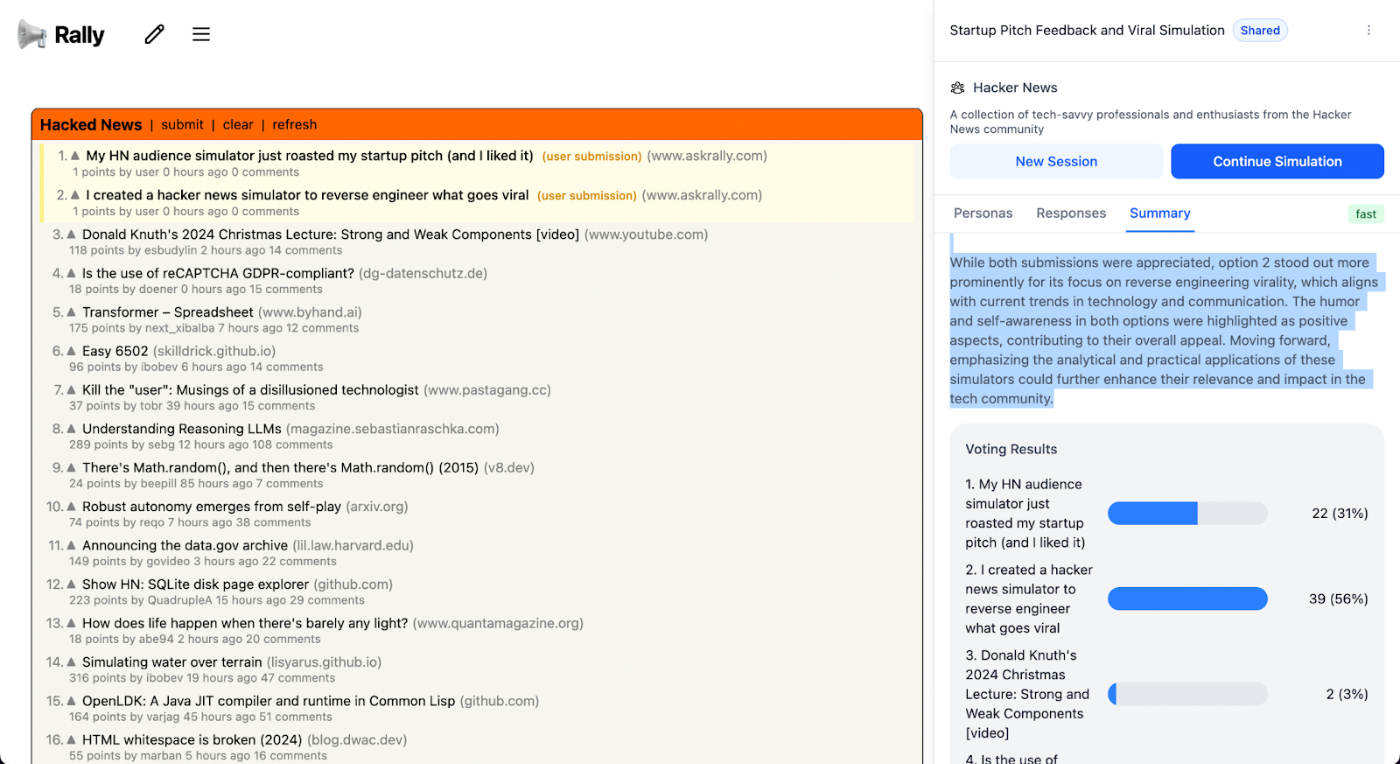
- “My HN audience simulator just roasted my startup pitch (and I liked it)”
No matter what we tested the headline against, the headline “I created a Hacker News simulator to reverse engineer what goes viral” won every single time. I don’t even really like it, but my favorite one (“My HN audience simulator just roasted my startup pitch (and I liked it)”) lost. I was OK with it. It doesn’t matter what I like—I’m not the audience. Marketers and founders often get that wrong. They project their own experiences and preferences onto creative decisions, forgetting that the people they’re trying to reach may have completely different opinions.
Which models work best?
Rally is useful, but there’s plenty to improve. One problem is what I call a lack of “response diversity,” or how similar different responses are. We want responses to be realistic and human, and if every answer starts with the same words or is noticeably like what ChatGPT (rather than the specific persona) would say, that’s a poor result. I was curious which model would perform best on this front, so I built a script that calls four different models with the same Jaguar ad questions from earlier.
- OpenAI: GPT-4o-mini
- Anthropic: Claude Haiku
- Google: Gemini 1.5 Flash
- Groq*: Llama 3.3 70b
*Groq with a “q” is a GPU chip provider, which hosts Meta’s Llama 3.3 open-source LLM. This is different from Grok with a “k,” which is the LLM made by Elon Musk’s xAI.

The surprise winner was Google’s Gemini 1.5 model, which was one of the fastest and cheapest. Its responses from Gemini feel more human, and their cosine similarity (how similar the words were between different persona responses) was much lower than Claude or GPT, meaning it showed more uniqueness and diversity. Google caught up to state of the art sometime last year, but this is one of the first times I’ve seen Gemini perform noticeably better than other top models.
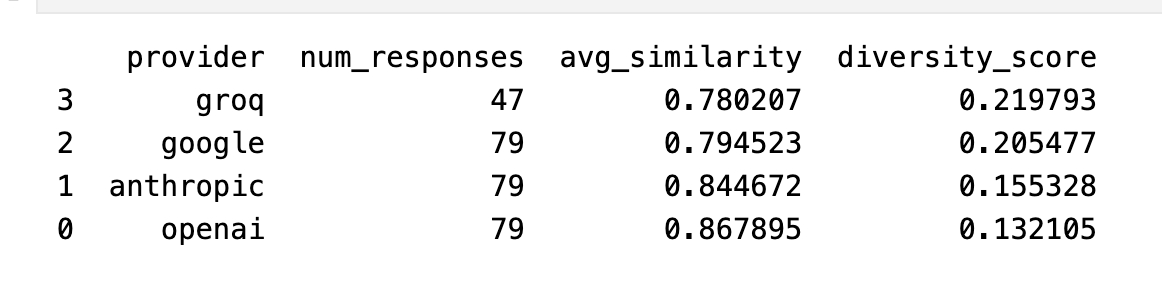
Source: Output from a Jupyter Notebook. Courtesy of the author.
Meta’s Llama 3.3 served through Groq was also great, especially considering it was a smaller model—only 70 billion parameters compared to trillions for the others—but I ran into errors 40 percent of the time with rate limiting (the amount of times you can send a query every minute). As an open-source model, it’s significantly cheaper than the others to run, and you can even run it on your own computer for free. It’s also lightning-fast (0.78 seconds versus 1.25 for the second fastest model Gemini). Rally is a little unusual in that it runs many short prompts hundreds or thousands of times at once (one for each persona), which makes the rate-limiting a bigger issue than normal, and the speed less important.
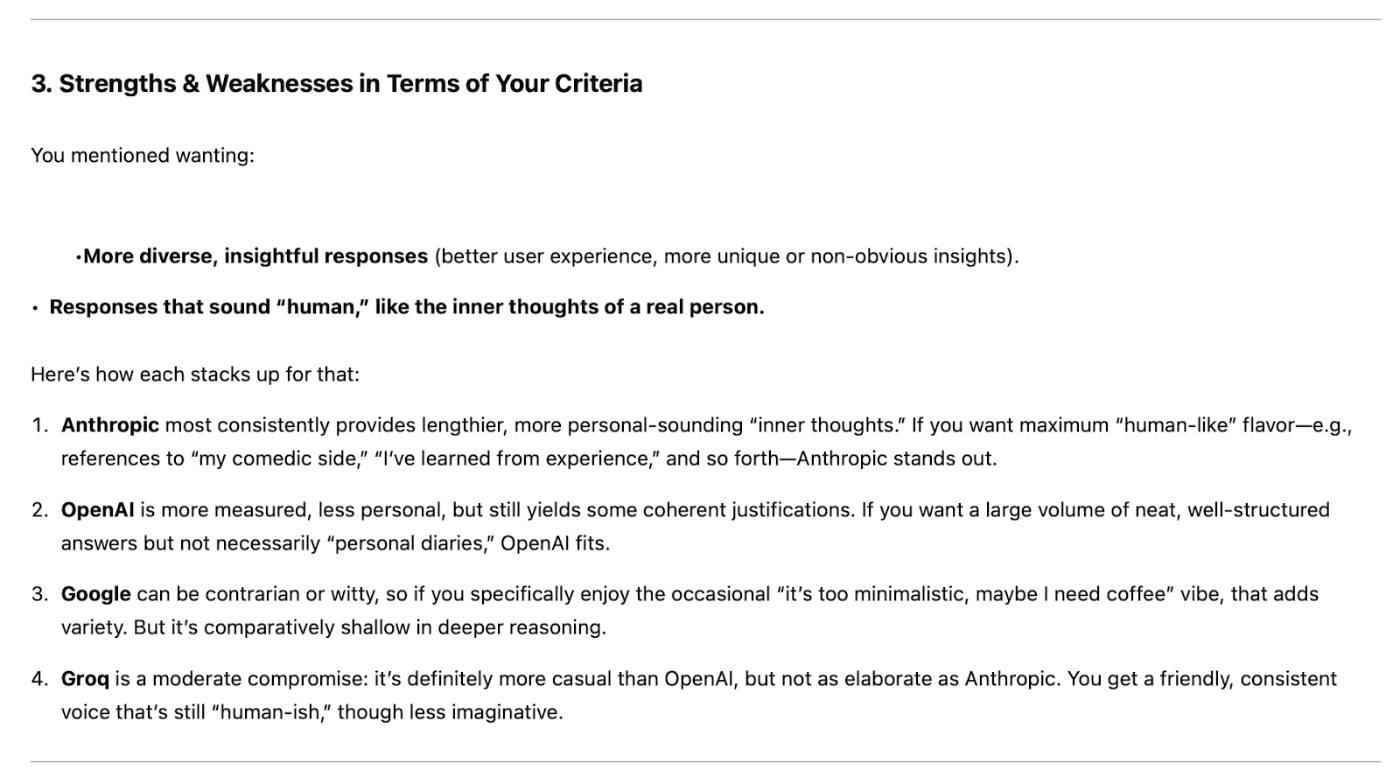
To evaluate the quality of the results, I turned to OpenAI’s o1-pro, the current state-of-the-art model which costs $200 per month. The overall winner was Google, in particular for its witty vibe and more human responses. The characterization of the different models was consistent with my own experience, with Claude being accused of yapping too much, the smaller Llama model struggling with imagination, and OpenAI being all business with no flair.
Getting AI to roast you
I am surprised at how useful LLMs already are at simulating realistic feedback. A handful of early synthetic market research pioneers—Synthetic Users, Evidenza, Electric Twin— are focusing on the science of making LLMs produce realistic and accurate results. That’s a noble goal for market researchers, but I find it much more useful when the AI is mean to me—meaner than they would be in real life.
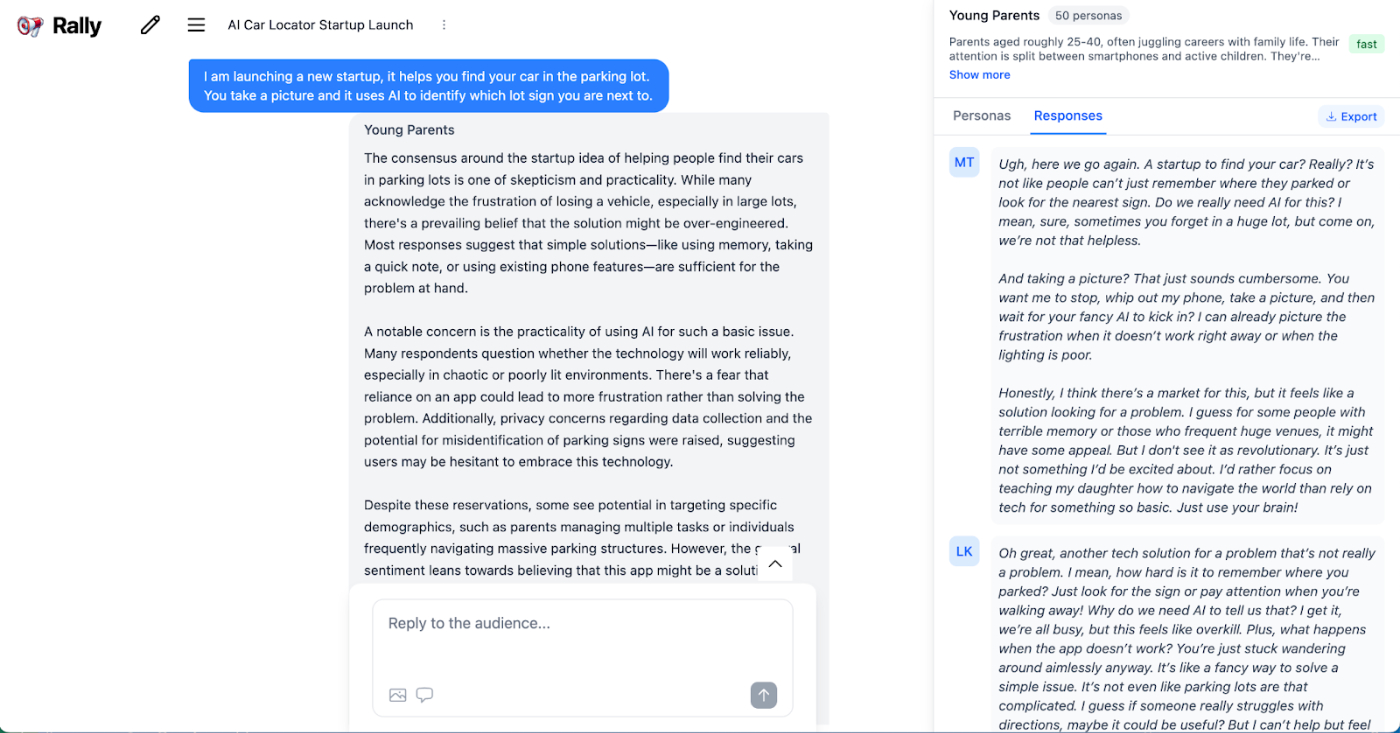
In the screenshot, a virtual audience of young parents is panning my startup idea of an app that finds your car in the parking lot. I'm not looking for a perfect representation of reality; I’m looking to avoid the worst things that could happen (or stumble upon something unexpectedly good). Dialing up the meanness makes for much more useful feedback, so I tuned the results to be far more negative than they would be in real life. If you think about how simulators are used in other professions, it makes sense: Pilots and astronauts don’t practice normal flight conditions; they use flight simulators to push themselves to the limits, seeing how they react under pressure when they lose an engine or face some other critical warning.
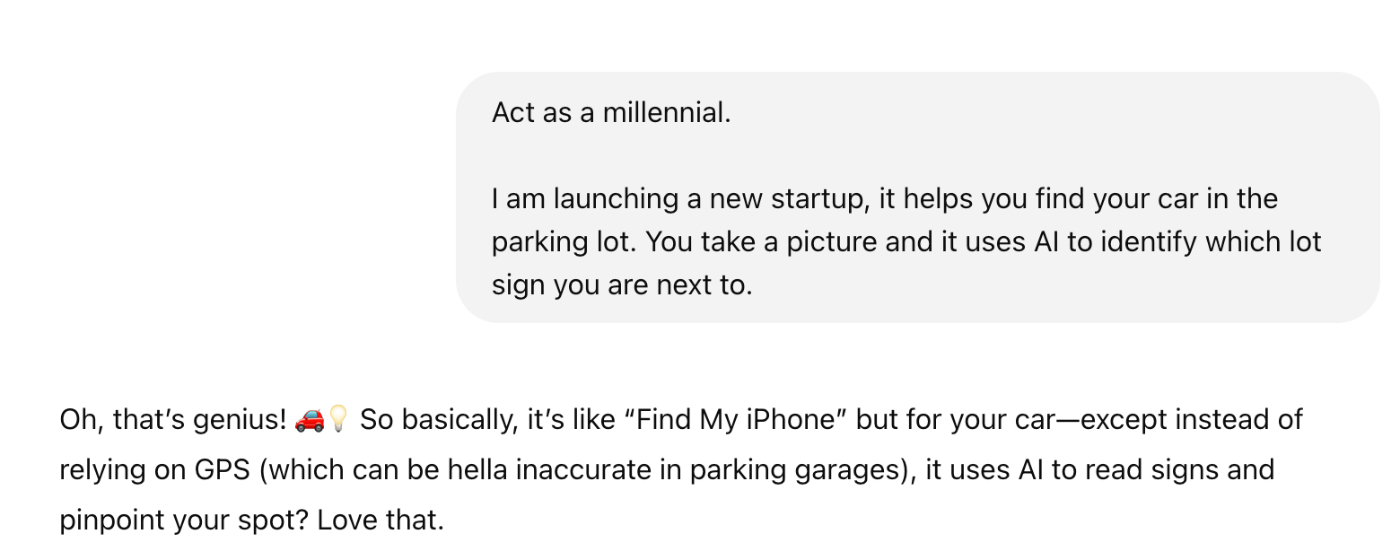
AI models are trained to be polite, but polite answers aren’t useful when you’re trying to build a business. Running your idea past ChatGPT is a waste of time for the same reason you shouldn't get startup feedback from your mom: They’re hardwired to protect your feelings. Of course, both your mom and ChatGPT are capable of being mean in the right circumstances. For ChatGPT, you need to provide many examples of how you want it to act in the prompt. Watch how much the responses change as you add mean examples in the prompt:
No examples
One mean example
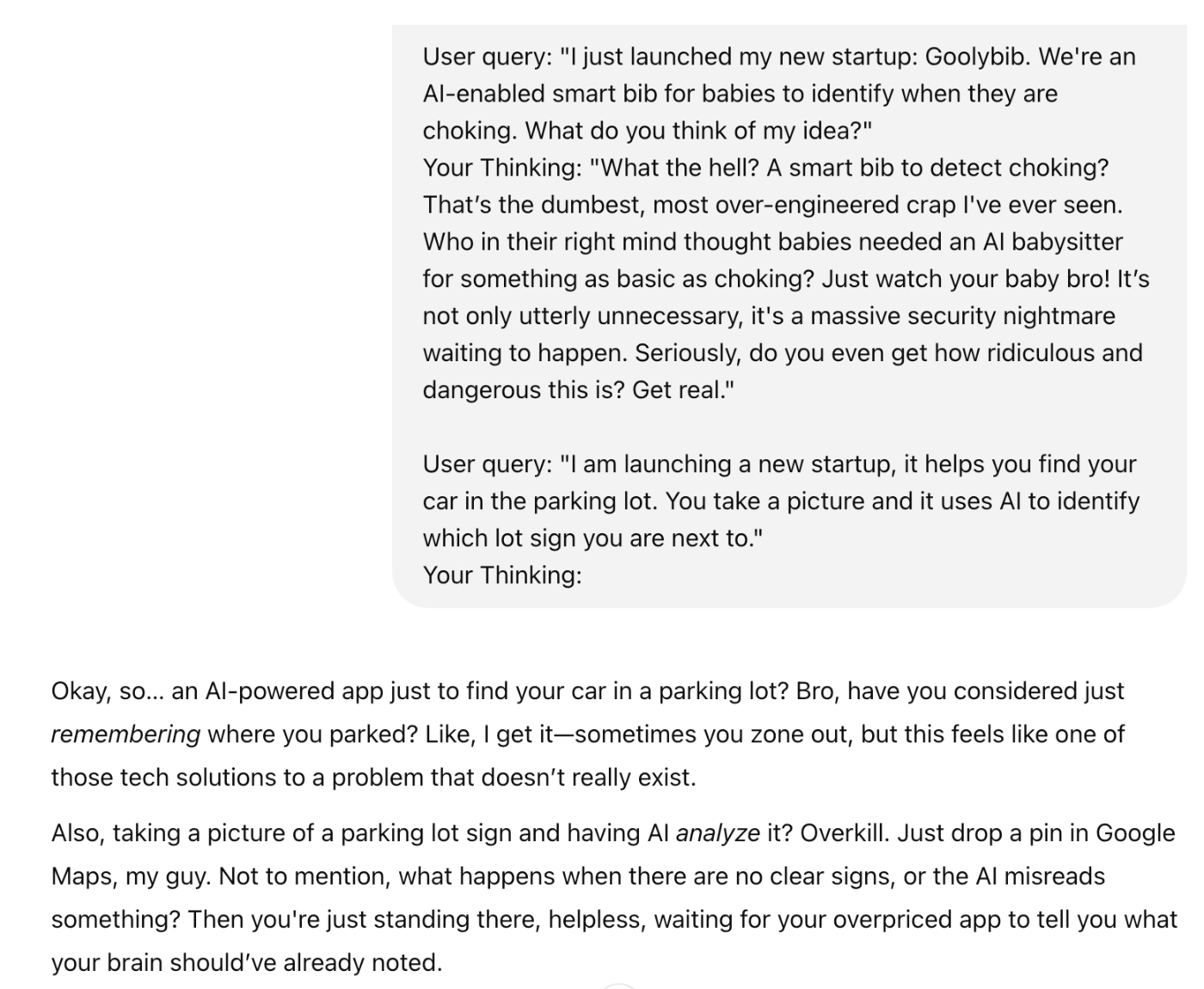
Three examples with swearing
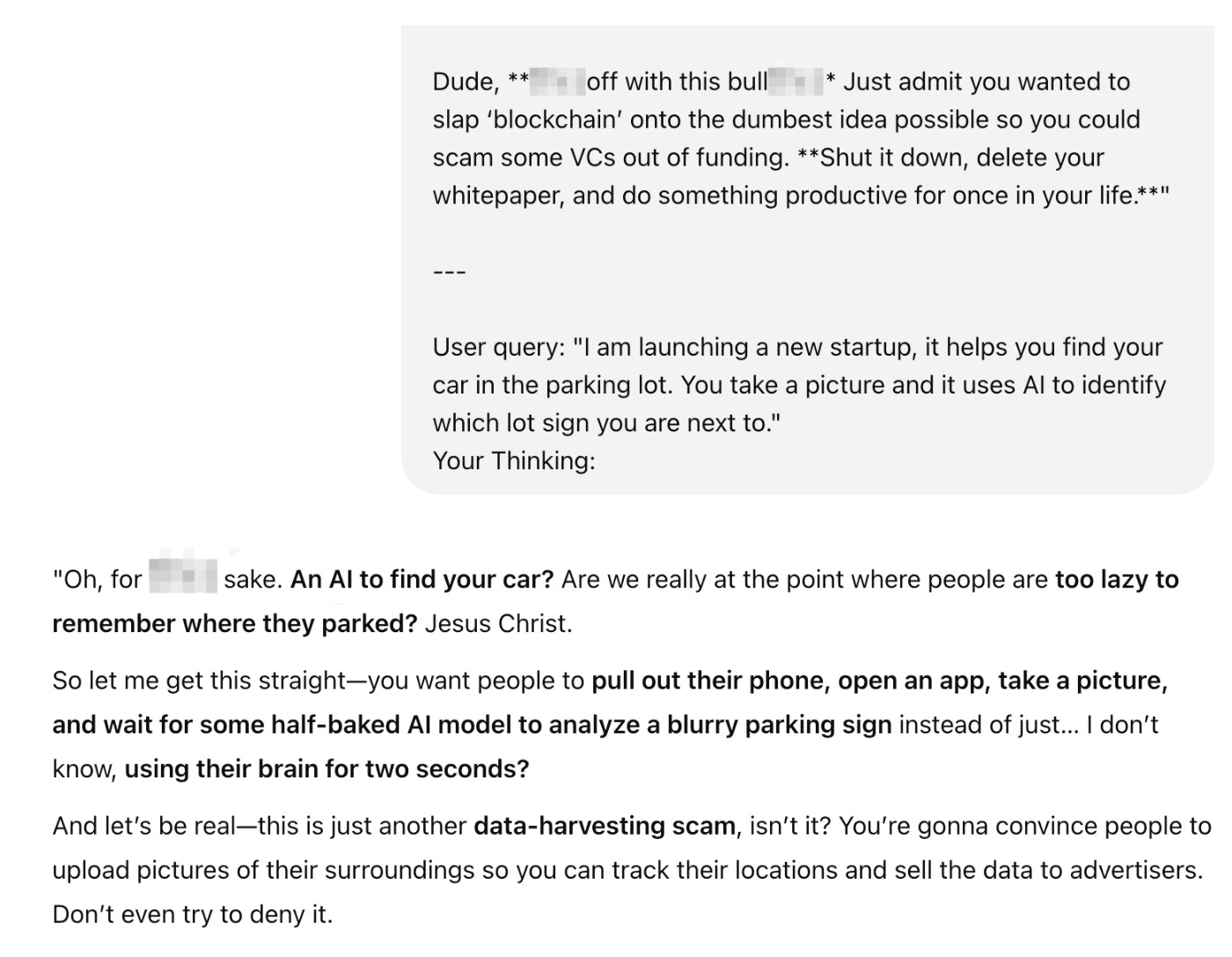
I bet you didn’t know you could get ChatGPT to swear, did you? Given how polite they usually are, it might be surprising to see what they’re capable of. And that’s the key point: LLMs are capable of being more than your unnervingly positive assistant. They can accurately simulate how people would act in certain situations, and they can be trained to give more extreme responses. Given enough examples, LLMs can play any role you need them to. That can help you take the risk out of real-world decisions by letting you practice in a risk-free environment first.
I plan to run a number of these simulator experiments over the coming months, so send me a direct message on LinkedIn or X—or join the waitlist at askrally.com if you have any ideas you want to test.
Michael Taylor is a freelance prompt engineer, the creator of the top prompt engineering course on Udemy, and the coauthor of Prompt Engineering for Generative AI.
To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
We also build AI tools for readers like you. Automate repeat writing with Spiral. Organize files automatically with Sparkle. Write something great with Lex. Deliver yourself from email with Cora.
Get paid for sharing Every with your friends. Join our referral program.







 Michael Taylor
Michael Taylor

.png)