
Many AI investors are betting that the biggest AI models will win—that scale and compute beat everything else. But recent research and market moves suggest otherwise. Alex Duffy, who runs a company that uses games to make AI models better, explains what he’s seeing from inside this market—and why the data your company already has might be worth more than you think.—Kate Lee
My friend recently received a strange email. The sender, someone at a large data provider for AI labs, wanted to know if my friend could share data on things like the number of Dropbox files his company had stored or the number of tickets it had processed on Zendesk. Compensation, commensurate with the data, was promised.
He showed me the email, curious. To me, the founder of a company that sells data and environments to AI companies to help them train models better, this was just another sign of the robust market forming for making AI better.
Reddit, Shutterstock, and News Corp are making hundreds of millions a year licensing their high-quality data to companies training AI, and those contracts are growing about 20 percent annually, according to their quarterly filings. News Corp’s CEO put it bluntly: “We’re essentially an input company [for AI].”
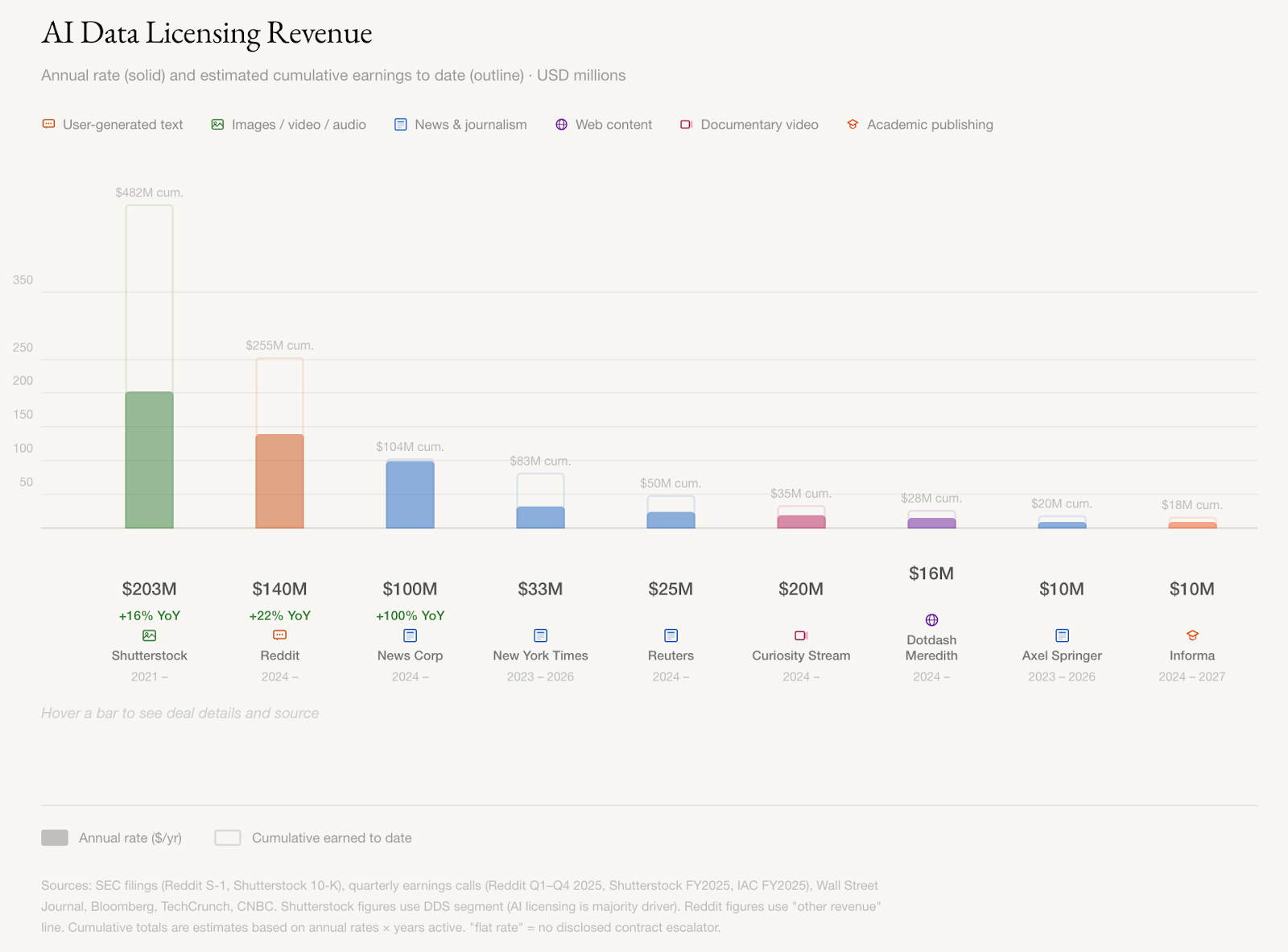
Academic publishers, documentary archives, game studios, and companies sitting on years of enterprise data have all been courted for the seeds of intelligence needed to train the next generation of models. Mercor, which provides data to AI labs for training, became one of the fastest-growing companies in history before losing four terabytes of data to hackers last week. Competitors Turing, Handshake, and SID.ai are scrambling to fill the gap, reaching out to founders and anyone with access to buy operational data, similar to the request my friend received.
While some experts have speculated that general models will win out in performance over specialized models—that scale and compute will beat curation—the success of these companies shows that the market is making a more nuanced bet.
A small model trained on fewer than 2,000 examples from real lawyers, bankers, and consultants recently beat all but the best frontier models on corporate legal work, at a fraction of the price, since they used an open-source model and now only face the cost of running it.
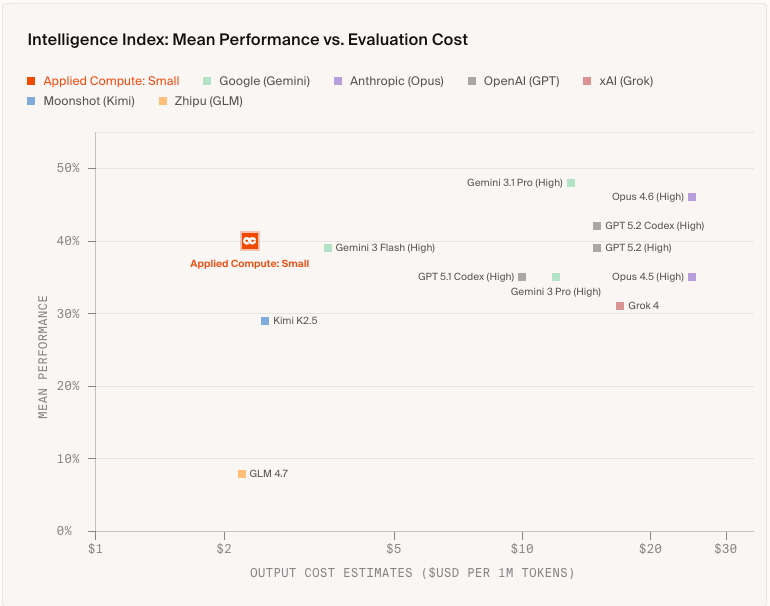
More companies are racing to catalogue and operationalize human knowledge, and whoever leads this market may shape which ideas, which history, and whose principles inform the most powerful tools we’ve ever built.

How to stop babysitting your agent
Agents can generate code. Getting it right for your system, team conventions, and past decisions is the hard part. You end up wasting time and tokens in the correction loops. More MCPs, rules, and bigger context windows give agents access to information, but not understanding. The teams pulling ahead have an organizational context engine to give agents exactly what they need for the task at hand.
Join us for a free webinar on April 23 to see:
- Where teams get stuck on the AI maturity curve and why common fixes fall short
- How a context engine solves for quality, efficiency, and cost
- Live demo: the same coding task with and without an organizational context engine
If you want to maximize the value you get from AI agents, this one is worth your time.
The data with value
The data sources with the most value share two traits: They’re high quality, and they keep growing. Reddit gets new posts. Shutterstock gets new image uploads. Games generate data from new sessions that reflect millions of human decisions. Models need to keep learning, and they need to learn from material that showcases intelligence at work.
The demands of AI labs can also influence what data has value—they are the biggest buyers. Currently, that is any data related to software engineering and math. If you can build an AI that writes excellent code and reasons through complex problems, you can use it to help build the next, better AI. That recursive loop is why labs are pouring so much attention into software engineering and math. Ahead of upcoming IPOs, the labs have widened the scope of their interest to “economically valuable work” in industries such as healthcare, professional services, and defense.
What makes a model great
So far, no one—not the labs, not anyone on X—has a settled definition of what makes a model great and what data is needed to get us there.
So the field is wide open for individuals to have a significant say in what models should prioritize, therefore shaping the future of AI. Do you want AI to handle customer service, use a browser, or draw a pelican riding a bicycle?
On the flip side, the lack of consensus means that conventional wisdom and social pressure have so far been large influences in what capabilities and skills we look for in models. Ultimately, however, what makes a model great is that it’s good at what people care about and get value from doing, a measure that will change over time. It will also influence which data has value for training models.
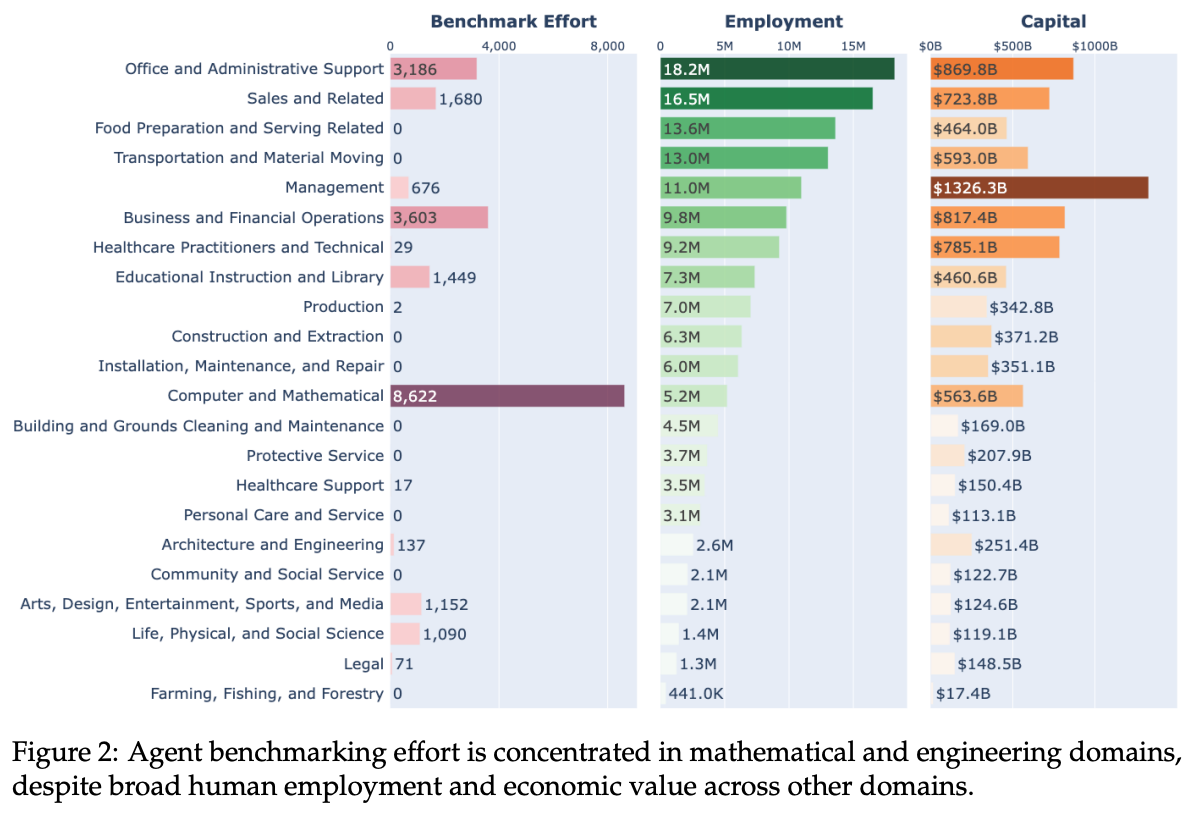
Researchers at Carnegie Mellon University and Stanford University recently mapped existing benchmarks against what people actually get paid to do, and the gaps are enormous. Programming and math are massively overrepresented. AI’s suitability and performance at most work—including most of what you or your organization does every day, from planning a business trip to crunching data—has never been measured at all.
But anything we can measure, we can improve. These discrepancies are also where the next wave of valuable data is hiding. The groups that figure out how to measure those areas first will set the bar for it for a while and gain serious soft power.
How do you get value out of your data?
If you’re running a company with proprietary data, you have two paths. First, you can license it to a lab. Second, use it yourself. This data could be call transcripts that include the context of your decisions, support tickets that reveal your internal processes, or documents that lay out how you make budgetary decisions.
More teams are doing both. Cursor, Shopify, Pinterest, Cognition, and others are already training their own models on open foundations. The math makes sense for businesses. These models are cheaper and often better at the specific job, intellectual property stays in-house, and every use generates more training data that can be captured to improve the model even further. This flywheel is a moat.
The tools for this kind of training get easier every month. Companies like Prime Intellect, Unsloth, and Thinking Machines (Tinker) are building entire businesses around helping teams that aren’t AI labs train models that feel like they came from one.
Where this lands isn’t settled. Scale might keep winning, but the likely answer is that two paths coexist. Most tasks will run on AI that’s good enough, while fields like national security, medicine, and materials science will pay top dollar for the best model on earth. The teams that understand what their data is worth, and what it could become, are positioned either way.
If you want to find out where you stand, start with a simple audit: What does your company generate every day that a model couldn’t find anywhere else? This could include call transcripts where experts explain their reasoning, edge cases that your support team has solved, and documents that explain why certain decisions were made. That inventory is the first draft of either a licensing conversation or a training run.
There’s more at stake than revenue, as well. The companies that win this market end up doing something unusual: They become custodians of what humans know and how we think. They decide what gets measured, what gets preserved, and what gets fed into systems that more people use every day to make real decisions.
With that position comes responsibility—the responsibility to make sure we are keeping AI pointed at what people really need, and making sure the breadth of human experience shows up in the data, including the parts hardest to capture.
Most of those decisions haven’t been made yet. The people paying attention now are the ones who will get to make them.
Alex Duffy is the cofounder and CEO of Good Start Labs and a contributing writer. To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
For sponsorship opportunities, reach out to [email protected].
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools



 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software

 Alex Duffy
Alex Duffy

Comments
Don't have an account? Sign up!