
Sponsored By: Reflect
This article is brought to you by Reflect, a beautifully designed note-taking app that helps you to keep track of everything, from meeting notes to Kindle highlights.
If you want to build a sustaining advantage in AI the conventional wisdom says you have to build the technology required for a powerful model. But a powerful model is not just a function of technology. It’s also a function of your willingness to get sued.
We’re already at a point in the development of AI where its limitations are not always about what the technology is capable of. Instead, limits are self-imposed as a way to mitigate business (and societal) risk.
We should be talking more about that when we think about where sustainable advantages will accrue and to whom.
. . .
ChatGPT is a great example. It is awesomely powerful, but it’s also profoundly limited. It’s limitations though, are not mostly technological. They’re intentional.
On the awesome side, it saved me ten hours of programming for a project I used it on this weekend. But for other use cases it completely fails:
Again, this is not a limitation of the underlying technology. In both of these cases it’s quite possible for the model to return a result that would plausibly answer my question. But it’s been explicitly trained to not do that.
The reason ChatGPT is so popular is because OpenAI finally packaged and released a version of GPT-3’s technology in a way that was open and user-friendly enough for users to finally see how powerful it was.
The problem is, if you build a chat bot that gets massively popular, the risk surface area for it saying things that are risky, harmful, or false goes up considerably. But, it’s very hard to get rid of the ability to use a model for harmful or risky things without also making it less powerful for other things. So as the days have gone on we’ve seen ChatGPT get less powerful for certain kinds of questions as they fix holes and prompt injection attacks.
It’s sort of like the tendency of politicians and business leaders to say less meaningful and more vague things as they get more powerful and have a larger constituency:
The bigger and more popular ChatGPT gets, the bigger the incentive is to limit what it says so that it doesn’t cause PR blowback, harm to users, or create massive legal risk for OpenAI. It is to OpenAI’s credit that they care about this deeply, and are trying to mitigate these risks to the extent that they can.
But, there’s another countervailing incentive working in the exact opposite direction: users and developers will want to use the model with the fewest number of restrictions on it—all else equal.
A great example of this has already played out in the image generator space.
. . .
Sponsored By: Reflect
This article is brought to you by Reflect, a beautifully designed note-taking app that helps you to keep track of everything, from meeting notes to Kindle highlights.
If you want to build a sustaining advantage in AI the conventional wisdom says you have to build the technology required for a powerful model. But a powerful model is not just a function of technology. It’s also a function of your willingness to get sued.
We’re already at a point in the development of AI where its limitations are not always about what the technology is capable of. Instead, limits are self-imposed as a way to mitigate business (and societal) risk.
We should be talking more about that when we think about where sustainable advantages will accrue and to whom.
. . .
ChatGPT is a great example. It is awesomely powerful, but it’s also profoundly limited. It’s limitations though, are not mostly technological. They’re intentional.
On the awesome side, it saved me ten hours of programming for a project I used it on this weekend. But for other use cases it completely fails:
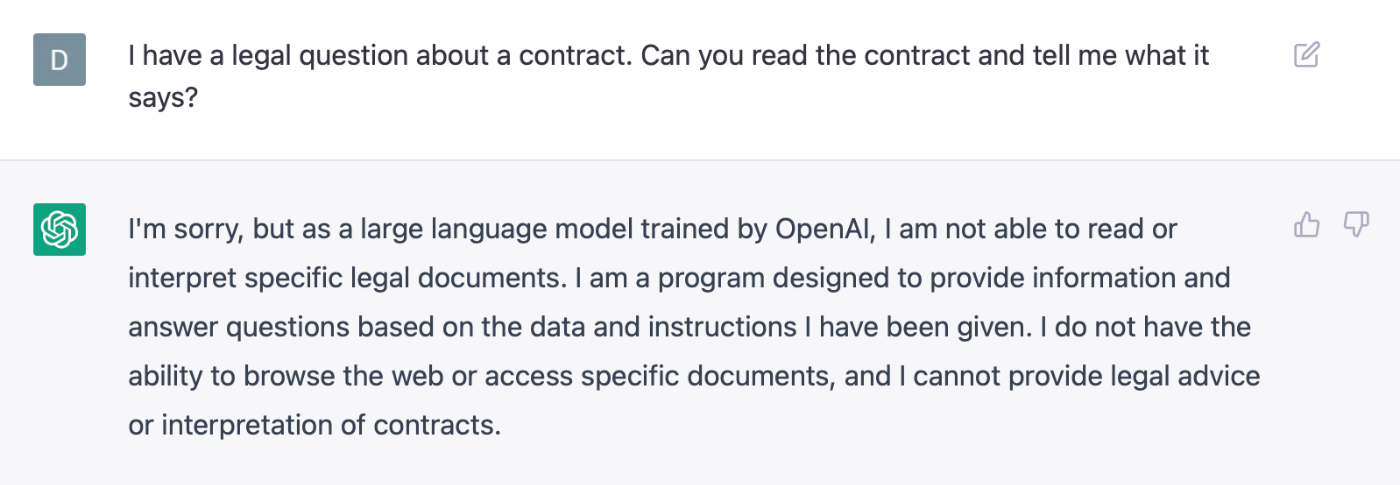
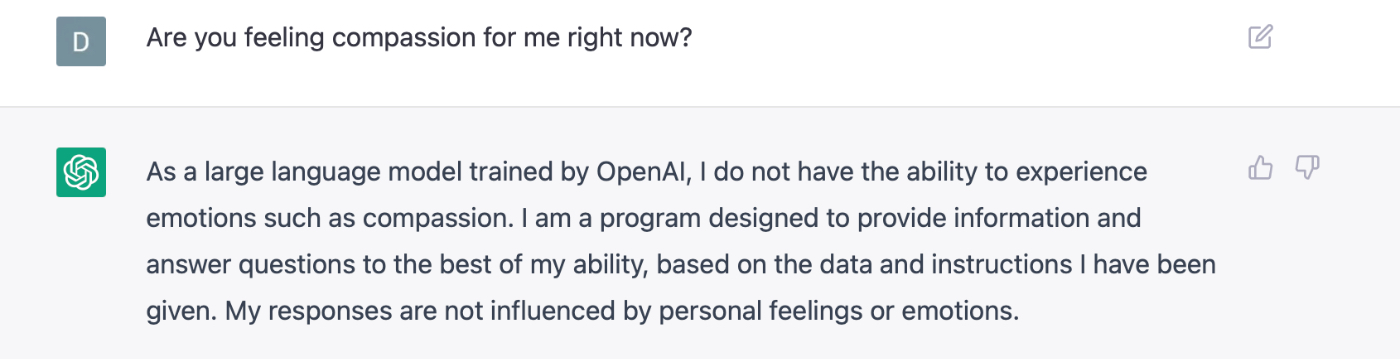
Again, this is not a limitation of the underlying technology. In both of these cases it’s quite possible for the model to return a result that would plausibly answer my question. But it’s been explicitly trained to not do that.
The reason ChatGPT is so popular is because OpenAI finally packaged and released a version of GPT-3’s technology in a way that was open and user-friendly enough for users to finally see how powerful it was.
The problem is, if you build a chat bot that gets massively popular, the risk surface area for it saying things that are risky, harmful, or false goes up considerably. But, it’s very hard to get rid of the ability to use a model for harmful or risky things without also making it less powerful for other things. So as the days have gone on we’ve seen ChatGPT get less powerful for certain kinds of questions as they fix holes and prompt injection attacks.
Reflect is a fast note-taking app designed to model the way you think. Use it as a personal CRM, as a way of taking meeting-notes, or just generally to keep track of everything in your life.
Reflect has integrations into all your favorite tools (calendar, browser, Kindle), so you can always find what you’ve read and researched. We work online or offline, desktop or mobile.
Think faster and clearer with Reflect.
It’s sort of like the tendency of politicians and business leaders to say less meaningful and more vague things as they get more powerful and have a larger constituency:
The bigger and more popular ChatGPT gets, the bigger the incentive is to limit what it says so that it doesn’t cause PR blowback, harm to users, or create massive legal risk for OpenAI. It is to OpenAI’s credit that they care about this deeply, and are trying to mitigate these risks to the extent that they can.
But, there’s another countervailing incentive working in the exact opposite direction: users and developers will want to use the model with the fewest number of restrictions on it—all else equal.
A great example of this has already played out in the image generator space.
. . .
DALL·E 2 was the first image generator to hit the market and it generated massive buzz over the summer:
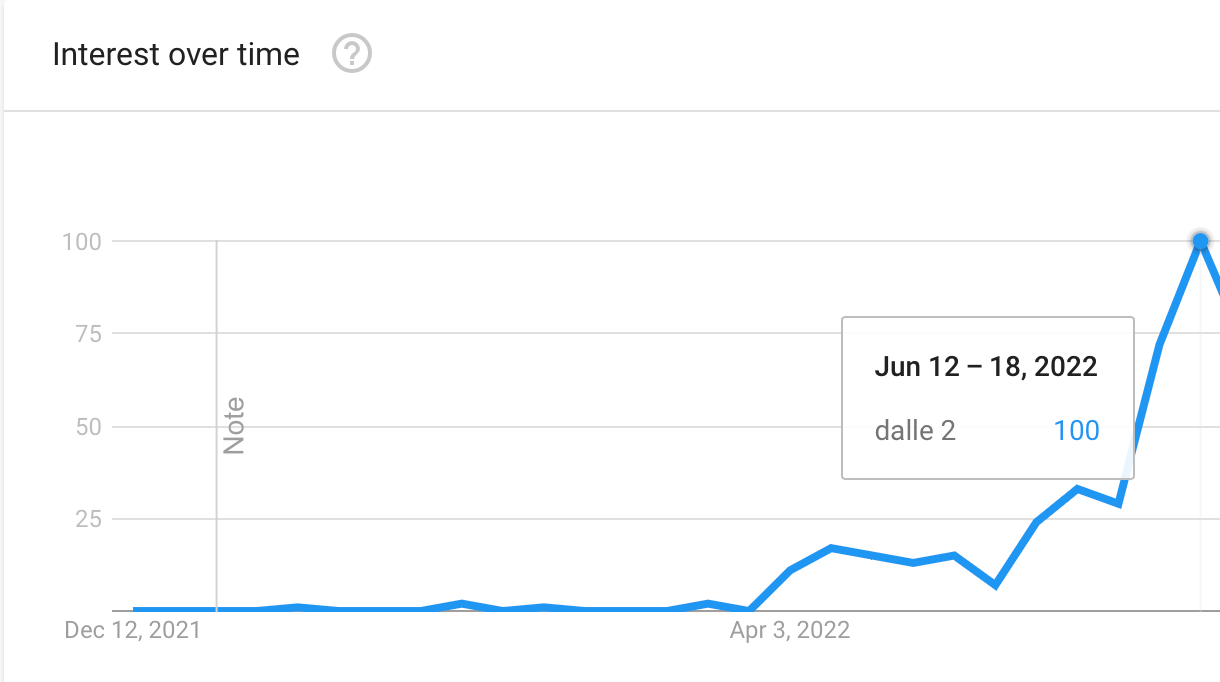
But its popularity (as measured by Google Searches) peaked and flatlined over the successive months:
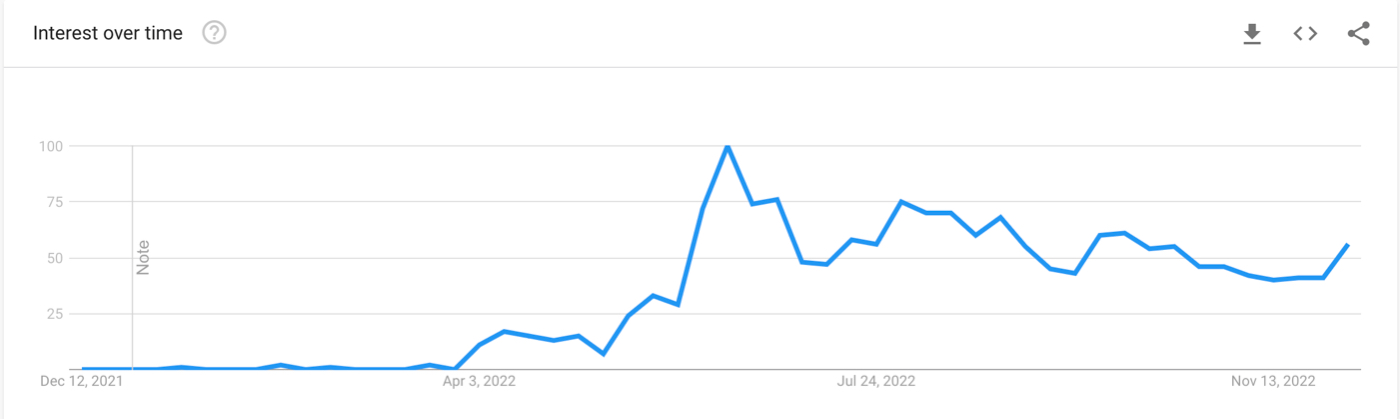
Why? DALL·E was a limited to being invite-only, and toward the end of the summer Stable Diffusion, an open-source public access version of the same technology was released. Suddenly, anyone could run the technology on their own computer and could use it to generate whatever kinds of images they wanted with no restrictions. The result was predictable:
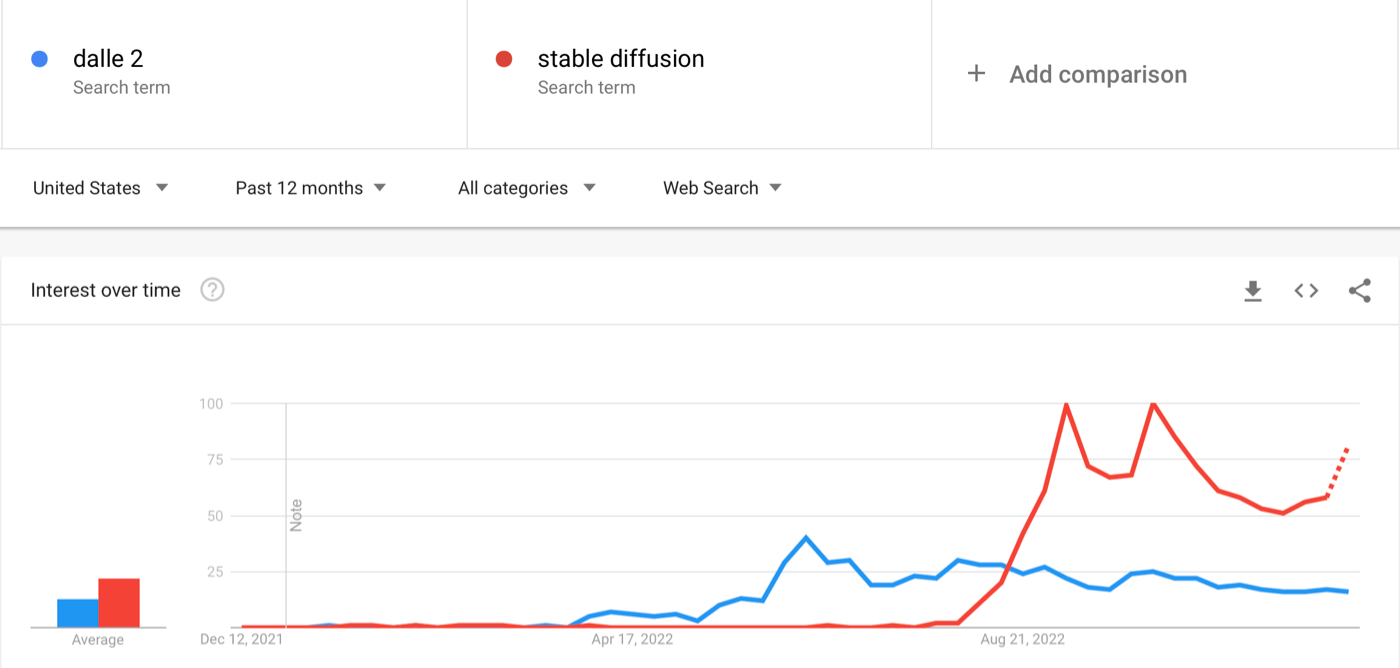
Soon after Stable Diffusion was released to the public, DALL·E became open access. But by then it was too late.
What happened?
Stable Diffusion was willing to take on the risk, legal and moral, of releasing this technology to the public without restriction. And its popularity was cemented because of it.
. . .
There is a corollary to this dynamic in social media, as covered by my colleague Evan in his piece Content Moderation Double-Bind Theory.
All social media companies have policies that limit what can be said on their platform. The closer a piece of content is to the moderation line, the more engagement it generates.
Here’s Mark Zuckerberg describing the issue:
“Our research suggests that no matter where we draw the lines for what is allowed, as a piece of content gets close to that line, people will engage with it more on average [emphasis added]—even when they tell us afterwards they don't like the content.”
And here’s a little graph that visualizes it:
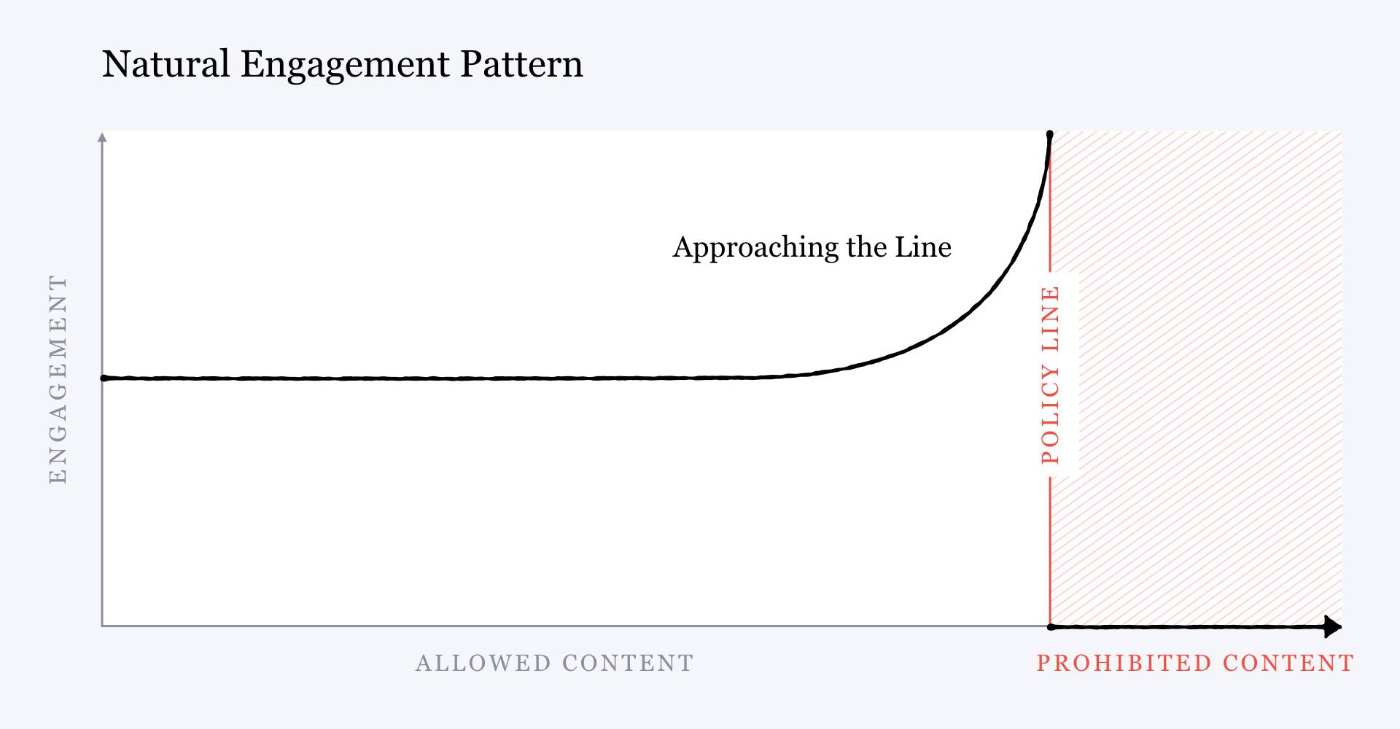
This creates what Evan describes as, “a content Darwinism where the edgy thrive.” He continues, “The people who don’t create content that’s close to the line tend to either pivot towards the edge, go out of business, or hit an audience plateau earlier than they would have if they were more shameless.”
There are a lot of similarities here to the companies creating and releasing these models. There is a natural pressure to release them with as few limitations as possible because the edgier the responses, the more user engagement it will create.
Of course, once the model gets popular and there is significantly more to lose for the company that creates it there will be pressure to restrict it away from the very things that made it popular in the first place.
. . .
The trick here is going to be finding clever ways to distribute the risk. Open sourcing the model is one obvious route. As mentioned earlier, Stable Diffusion already pursuing this.
If you release the trained model and let people run it on their own computers, you get a lot of the benefit of giving users freedom without assuming as much of the liability (both perceived and actual) for when things go wrong.
Another interesting way to distribute risk is to have a thriving 3rd party ecosystem of apps based on your model.
Right now, if I ask ChatGPT a legal question it will demur. But GPT-3, the foundational model at the heart of ChatGPT, is available for any developer to use. You could imagine a world where, so long as you are taking responsibility for the completions that get generated, OpenAI allows a 3rd party developer to get GPT-3 to answer questions about the law.
This is probably possible today with the right prompts and fine-tuning. A 3rd party focused on a legal chatbot that is willing to vet it and assume the risk of its responses is a way for OpenAI to unleash the power of the foundational model in a way that they might not do on their own.
You could imagine lots of different bots in different sectors like law, medicine, psychology, and more that are all able to access parts of the model’s power that OpenAI wouldn’t allow access to inside of ChatGPT or other tools that are intended general-use. This is good for OpenAI, and it's also good for founders who want to start large companies with OpenAI's technology.
If you can get good at making it say risky things in a specific area that you can vet thoroughly, and you're willing to take on that risk, then you have an advantage without having to build your own foundational model.
. . .
We’re very fortunate that so far the people who have built these models seem to be generally ethical people who are committed to answering thorny questions about how to balance safety with progress. (Here in particular, I’m thinking about OpenAI.)
Unfortunately, the current incentives are such that anyone who is willing to open things up faster and with less restrictions will win an advantage.
As a huge fan of this space I’m supremely excited to see what happens with these technologies. Morally, it’s upsetting that it less caution and fewer restrictions might win the day.
In either case, if you’re wondering where this space is going, and how models will be disseminated and used over time it’s important to remember: it’s not just about the progress in the technology. It’s also about who’s willing to get sued.
Ideas and Apps to
Thrive in the AI Age
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools



 Front-row access to the future of AI
Front-row access to the future of AI

Ideas and Apps to
Thrive in the AI Age
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators
Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools
Front-row access to the future of AI

 Dan Shipper
Dan Shipper



 Evan Armstrong
Evan Armstrong

Comments
Don't have an account? Sign up!