
Was this newsletter forwarded to you? Sign up to get it in your inbox.
I often wonder how predictable I am.
I like to think that my preferences in films and music, my interest in philosophy, or even the echoes of my childhood obsession with anime and manga define a pattern that's as unique as my fingerprint. Most of us walk around with some version of this assumption, I think. We may consciously cultivate our tastes, but at the end of the day we feel they're ineffable. No machine could learn to reproduce a pattern so nuanced, so tethered to our unique experience of the world.
But what if that's not true? What if my taste, and yours, is well within the reach of AI to understand—and to predict?
I've wrestled with some form of this question for years. Early in my career, I worked at a company building recommendation engines for e-commerce sites. I became fascinated by the idea of a universal discovery engine: an opposite of Google Search that would surface content you don't even know you want yet.
Building something like that would be transformative. When Netflix suggests a movie, instead of a just-okay recommendation, you'd end up binging everything the director has ever made. Every new song would hit you deep in your soul. It would be a profoundly more satisfying way to navigate the oceans of content at our fingertips, not to mention a huge business opportunity.
The explosion of generative AI made me wonder if machines had become sophisticated enough to power a discovery engine to encode and decode our tastes. To find out, I ran an experiment on myself.
Can taste be automated?
Before we get to the experiment, we need to address the taste discourse. AI is improving fast in acquiring a whole range of skills, but many smart people—including Every CEO Dan Shipper—have gravitated toward taste as a way that humans will continue to differentiate themselves from the machines.
Replicating taste with AI seems impossible because our real preferences hide in the shadows—we read without liking, enjoy without sharing. The platforms that know us best guard their data like dragons. And taste itself shapeshifts through lived experience: A chef's palate emerges from years of burnt soufflés and perfect reductions, from connecting flavors to emotional memories—creating judgments no algorithm can fake.
Our taste continually evolves, shifting with exposure to new influences, life experiences, and cultural trends. A music enthusiast who once dismissed electronica might develop an appreciation for it after attending a transformative live performance. A reader's literary preferences might expand dramatically during a period of personal upheaval.
While these barriers make automating taste seem hard, they don't necessarily make it unachievable. The very qualities that make taste difficult to replicate—its personal nature, evolution over time, and basis in lived experience—might provide the foundation for a new approach.
Why LLMs see what Netflix can't
Traditional recommendation engines work like a lazy matchmaker—"you watched sci-fi, here's more sci-fi." Netflix might know I watched three sci-fi movies last week, but it can't grasp why I loved the philosophical undertones in one while finding another's action sequences tedious. Facebook's algorithm might surface posts similar to others I've liked, but it misses the subtle distinction between content I genuinely find meaningful versus what I casually toss a "like" to while scrolling.
True taste operates at a much finer resolution. LLMs are different. They contain billions of parameters that encode rich contextual understanding about cultural references and subtle associations between concepts. Where a traditional collaborative filtering model might know that users who liked Movie A also liked Movie B, an LLM "understands why"—it "knows" that both films share noir aesthetics, feature morally ambiguous protagonists, or were influenced by German Expressionism.
This deep contextual knowledge, built from training on vast amounts of text, enables more sophisticated and personalized assessments of what aligns with an individual's taste.
So I decided to find out if this was true. Could an LLM actually predict what would catch my eye in my daily scroll? I gathered six months of my own browsing data and ran four experiments. The results were unsettling.
Testing my predictability: Four experiments with my browsing data
Was this newsletter forwarded to you? Sign up to get it in your inbox.
I often wonder how predictable I am.
I like to think that my preferences in films and music, my interest in philosophy, or even the echoes of my childhood obsession with anime and manga define a pattern that's as unique as my fingerprint. Most of us walk around with some version of this assumption, I think. We may consciously cultivate our tastes, but at the end of the day we feel they're ineffable. No machine could learn to reproduce a pattern so nuanced, so tethered to our unique experience of the world.
But what if that's not true? What if my taste, and yours, is well within the reach of AI to understand—and to predict?
I've wrestled with some form of this question for years. Early in my career, I worked at a company building recommendation engines for e-commerce sites. I became fascinated by the idea of a universal discovery engine: an opposite of Google Search that would surface content you don't even know you want yet.
Building something like that would be transformative. When Netflix suggests a movie, instead of a just-okay recommendation, you'd end up binging everything the director has ever made. Every new song would hit you deep in your soul. It would be a profoundly more satisfying way to navigate the oceans of content at our fingertips, not to mention a huge business opportunity.
The explosion of generative AI made me wonder if machines had become sophisticated enough to power a discovery engine to encode and decode our tastes. To find out, I ran an experiment on myself.

Make email your superpower
Not all emails are created equal—so why does our inbox treat them all the same? Cora is the most human way to email, turning your inbox into a story so you can focus on what matters and getting stuff done instead of on managing your inbox. Cora drafts responses to emails you need to respond to and briefs the rest.
Can taste be automated?
Before we get to the experiment, we need to address the taste discourse. AI is improving fast in acquiring a whole range of skills, but many smart people—including Every CEO Dan Shipper—have gravitated toward taste as a way that humans will continue to differentiate themselves from the machines.
Replicating taste with AI seems impossible because our real preferences hide in the shadows—we read without liking, enjoy without sharing. The platforms that know us best guard their data like dragons. And taste itself shapeshifts through lived experience: A chef's palate emerges from years of burnt soufflés and perfect reductions, from connecting flavors to emotional memories—creating judgments no algorithm can fake.
Our taste continually evolves, shifting with exposure to new influences, life experiences, and cultural trends. A music enthusiast who once dismissed electronica might develop an appreciation for it after attending a transformative live performance. A reader's literary preferences might expand dramatically during a period of personal upheaval.
While these barriers make automating taste seem hard, they don't necessarily make it unachievable. The very qualities that make taste difficult to replicate—its personal nature, evolution over time, and basis in lived experience—might provide the foundation for a new approach.
Why LLMs see what Netflix can't
Traditional recommendation engines work like a lazy matchmaker—"you watched sci-fi, here's more sci-fi." Netflix might know I watched three sci-fi movies last week, but it can't grasp why I loved the philosophical undertones in one while finding another's action sequences tedious. Facebook's algorithm might surface posts similar to others I've liked, but it misses the subtle distinction between content I genuinely find meaningful versus what I casually toss a "like" to while scrolling.
True taste operates at a much finer resolution. LLMs are different. They contain billions of parameters that encode rich contextual understanding about cultural references and subtle associations between concepts. Where a traditional collaborative filtering model might know that users who liked Movie A also liked Movie B, an LLM "understands why"—it "knows" that both films share noir aesthetics, feature morally ambiguous protagonists, or were influenced by German Expressionism.
This deep contextual knowledge, built from training on vast amounts of text, enables more sophisticated and personalized assessments of what aligns with an individual's taste.
So I decided to find out if this was true. Could an LLM actually predict what would catch my eye in my daily scroll? I gathered six months of my own browsing data and ran four experiments. The results were unsettling.
Testing my predictability: Four experiments with my browsing data
To test whether AI could predict my taste, I collected two datasets of my own online browsing behavior. Every time I upvote an article or save an article to read later, I'm making a judgment about whether that content is worth my attention. These datasets would provide a measurable starting point that captures something essential about my personal preferences.
The first was six months of my Hacker News upvotes, capturing both what I liked and, crucially, what I scrolled past without upvoting. The second was my Readwise Reader Shortlist, a two-tiered set of information about my preferences, containing both the articles I'd saved to read later while scanning the internet, and the subset that I actually read. In both cases, I liked less than 10 percent of what I saw, showing just how picky personal taste really is. Here’s what I learned:
Without context, AI was lost
When I asked models to predict which articles I'd find interesting without any background knowledge about me, they performed barely better than a coin flip on the Readwise shortlist dataset: GPT-4.1-mini achieved 50.7 percent accuracy and GPT-4.1 managed 52.2 percent. This near-random performance shows how hard it is to model what someone finds compelling without knowing anything about them.
The shortlist proved especially challenging because it required a second layer of curation, choosing the best content from articles I'd already saved to read later. The Hacker News dataset fared better at 65.5 percent, likely because the patterns were more obvious when choosing from all available posts rather than from pre-filtered content.
Adding a paragraph about my preferences radically changed the results
I took all the articles I'd liked from Readwise and combined them with everything ChatGPT had learned about me from our past conversations to create what I call a "taste rubric": a detailed description of what catches my attention and what doesn't.
When I gave the models this context about my preferences, their performance jumped dramatically. On the shortlist dataset, GPT-4.1-mini went from 56.7 percent to 67.2 percent accuracy, while GPT-4.1 improved even more, from 52.2 percent to 70.1 percent. The newer o3 model hit similar numbers, at 70.2 percent. For Hacker News, GPT-4.1 climbed from 65.5 percent to 76.2 percent.
The bigger models benefited more from having this context, which tracks: They have more capacity to process and apply nuanced preference patterns. It's like the difference between asking someone to "pick a movie for me" versus "pick a movie for me, knowing I love philosophical sci-fi but hate action sequences."
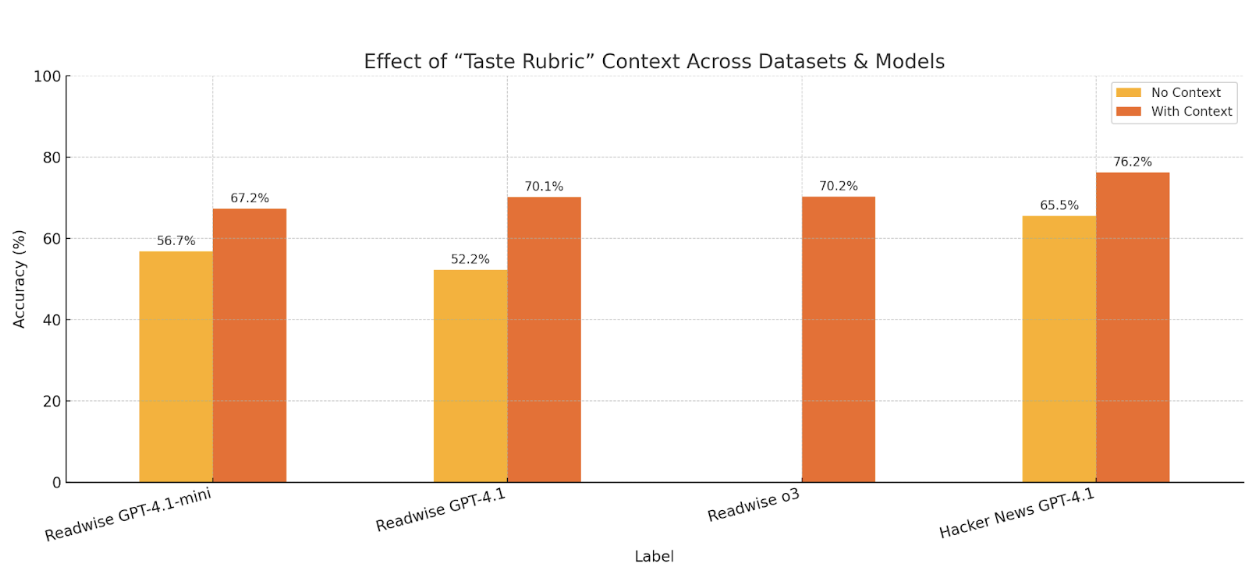
Even tiny tweaks to prompts pushed accuracy higher
I tried using DSPy, a framework that systematically optimizes prompts through trial and error. The improvements were modest but consistent. On the shortlist dataset, accuracy increased from 70.1 percent to 73.9 percent, while Hacker News went from 76.2 percent to 78.6 percent. While these aren't huge jumps like with the taste rubric, they show that even small tweaks to how you ask a question can result in better performance.
Comparisons worked even better than absolute judgments
Instead of asking, "Is this article interesting?" I asked, "Which of these two articles is more interesting?" This mirrors how we actually make choices in real life, and the results were striking. Without any context about my preferences, the models were basically guessing on the shortlist dataset (49.1 percent accuracy). But with my taste rubric, they jumped to 62.3 percent, and with DSPy optimization reached 62.9 percent.
The Hacker News pairwise comparisons performed even better. Starting from 58.7 percent without context, adding the taste rubric pushed accuracy to 77.3 percent, and DSPy optimization brought it all the way to 80.9 percent. This was the highest accuracy I achieved in any experiment. Comparative judgments may tap into something fundamental about how both humans and AI systems evaluate preferences. We're often better at saying, "I prefer A to B" than definitively stating, "A is good."
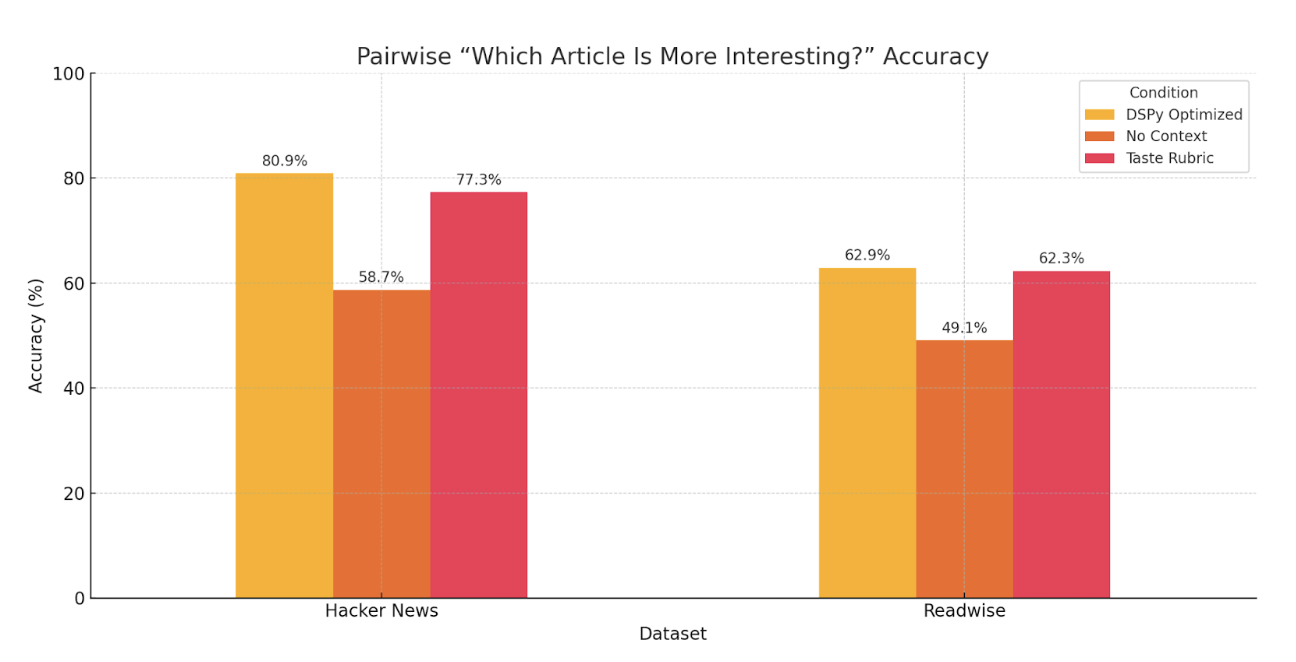
The 80 percent solution—and why the last 20 percent matters
The dramatic improvement from adding taste rubrics validates my core hypothesis: LLMs can leverage their vast knowledge to understand and apply individual preferences.
However, the experiments revealed important subtleties.
First, context matters enormously. Adding a simple description of my preferences—the taste rubric—boosted model accuracy by up to 18 percent.
Second, asking models to compare two items head-to-head worked better than having them judge items individually, suggesting that relative comparisons mirror how we actually make choices.
Most revealing was the performance gap between datasets: The AI could predict my Hacker News upvotes with 80 percent accuracy but struggled more with my Readwise shortlist decisions. This makes sense because Hacker News is mostly tech content, while my reading list spans everything from philosophy to fiction—a much wider band of possibility. The shortlist also required LLMs to make harder choices—just by being on the shortlist, I'd already indicated my interest, and I was asking it to pick out the best of the best.
There's plenty of room for improvement, though. We could give models richer context by including not just what I liked but why I liked it. We could build in feedback loops so the system gets better over time as it learns from its mistakes.
The predictable and the ineffable
I was both humbled and fascinated by what the experiments revealed about the nature of personal taste. First, I was struck by how poorly base models performed at predicting what I'd find interesting without any context. Their notion of "interestingness" was essentially random compared to mine, achieving barely 50 percent accuracy. This suggests that what we find compelling is far more personal than universal.
Yet I was equally surprised by how predictable I became once the models had context. With just one prompt describing my preferences, they could predict my Hacker News upvotes with better than 80 percent accuracy. It required no fine-tuning or training on thousands of examples—just a paragraph of text about what I like. It's unsettling to realize that your behavior, which feels so nuanced and personal, can be compressed into a prompt and replicated by a machine.
The fact that the models struggled more with predicting my Readwise shortlist decisions was particularly revealing. When I saved an article about consciousness or a profile of an obscure philosopher, would I actually read it? The AI could tell I was interested in philosophy, but distinguishing between the essay that would captivate me for an hour versus one I'd abandon after two paragraphs proved much harder.
AI systems are getting reasonably good at modeling general preferences, but true taste—those fine-grained distinctions we make within content we already find interesting—remains more elusive. The difference between 80 percent and 100 percent might seem small, but it contains everything that makes us uniquely ourselves: the unexpected connections, the irrational attractions, the moments when something just clicks for reasons we can't quite articulate.
For now, at least, the subtlest aspects of human taste remain just out of AI's reach. But that gap is shrinking faster than I expected. And I'm not entirely sure how I feel about that.
Edmar Ferriera is an entrepreneur-in-residence at Every. Previously he founded and sold Rock Content, a leading content marketing platform.
To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
We build AI tools for readers like you. Write brilliantly with Spiral. Organize files automatically with Sparkle. Deliver yourself from email with Cora.
We also do AI training, adoption, and innovation for companies. Work with us to bring AI into your organization.
Get paid for sharing Every with your friends. Join our referral program.
Ideas and Apps to
Thrive in the AI Age
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools



 Front-row access to the future of AI
Front-row access to the future of AI

Ideas and Apps to
Thrive in the AI Age
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators
Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools
Front-row access to the future of AI

 Danny Aziz
Danny Aziz

 Cassius Kiani
Cassius Kiani

 Naveen Naidu Mummana
Naveen Naidu Mummana
Comments
Don't have an account? Sign up!
Just wondering if including additional qualitative data may enrich or raise the prediction accuracy. Wiring style in mails, conversation story about prompting sequence and vibes, our blog or social posts or comments, podcast, and music favorites, or even our grocery or Amazon shopping list.