

Katie Parrott is a staff writer. She writes Working Overtime and contributes to Vibe Checks, Source Code, and Context Window.
The Fallacy of the 16-hour Agent
Plus: Perplexity’s rules for agent skills, the office politics of dictation, and creating a weekend AI piano coach
May 12, 2026 · 7 min readUpdated Jun 28, 2026
New data on long-horizon AI reliability just dropped, and depending on which chart you saw, you either think autonomous AI has arrived or it’s still years away. Today, we break down which version of the research to trust, plus Perplexity shares its methodology for building agent skills that don’t rot in production, Every CEO Dan Shipper turns his piano keyboard into a real-time Codex-powered music coach, and Gusto co-founder Edward Kim warns that the office of the future is going to sound more like a sales floor.—Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Signal
The 24/7 agent is nearly upon us—or is it?
The holy grail of agentic AI has been long-horizon reliability—an agent to which you can hand a task and trust to still be on the right thread hours later, when context has decayed and there’s no human in the loop to catch a wrong turn. METR, a nonprofit that measures AI capabilities, released an update to its research showing how close we are to that autonomous future.
One chart from the update circulating online shows an early preview of Anthropic’s next model, Mythos, blowing past existing models and the 16-hour range that METR’s benchmark suite can reliably test—literally breaking the scale.
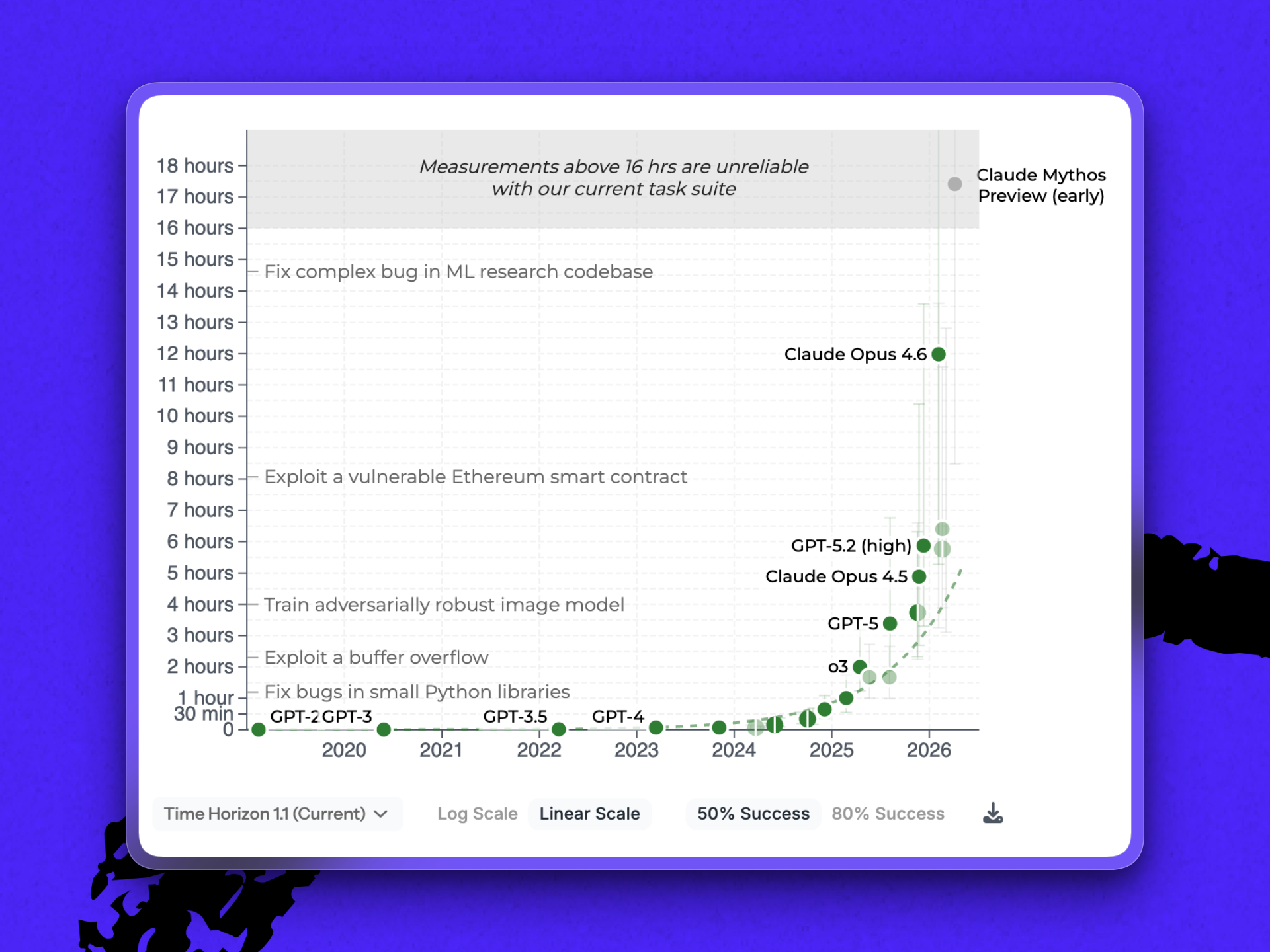
It’s important to note, however, that how many human hours a task takes is not the same as how long a model takes to run those same tasks. Duration, the way that METR’s benchmark uses it, stands in for difficulty. As the nonprofit writes in the report’s FAQ: “AI agents are typically several times faster than humans on tasks they complete successfully.”
That last bit—tasks completed successfully—adds another twist to the benchmark. The 16-plus hour measurement is based on a 50 percent success rate. A separate measurement of how LLMs perform at 80 percent reliability shows that Mythos can run tasks that would take humans a little over three hours. It’s a significant step up from the closest competitor measured, Gemini 3.1 Pro (METR doesn’t currently have measurements for Opus 4.7 or GPT-5.5). But it brings Mythos back down to earth.
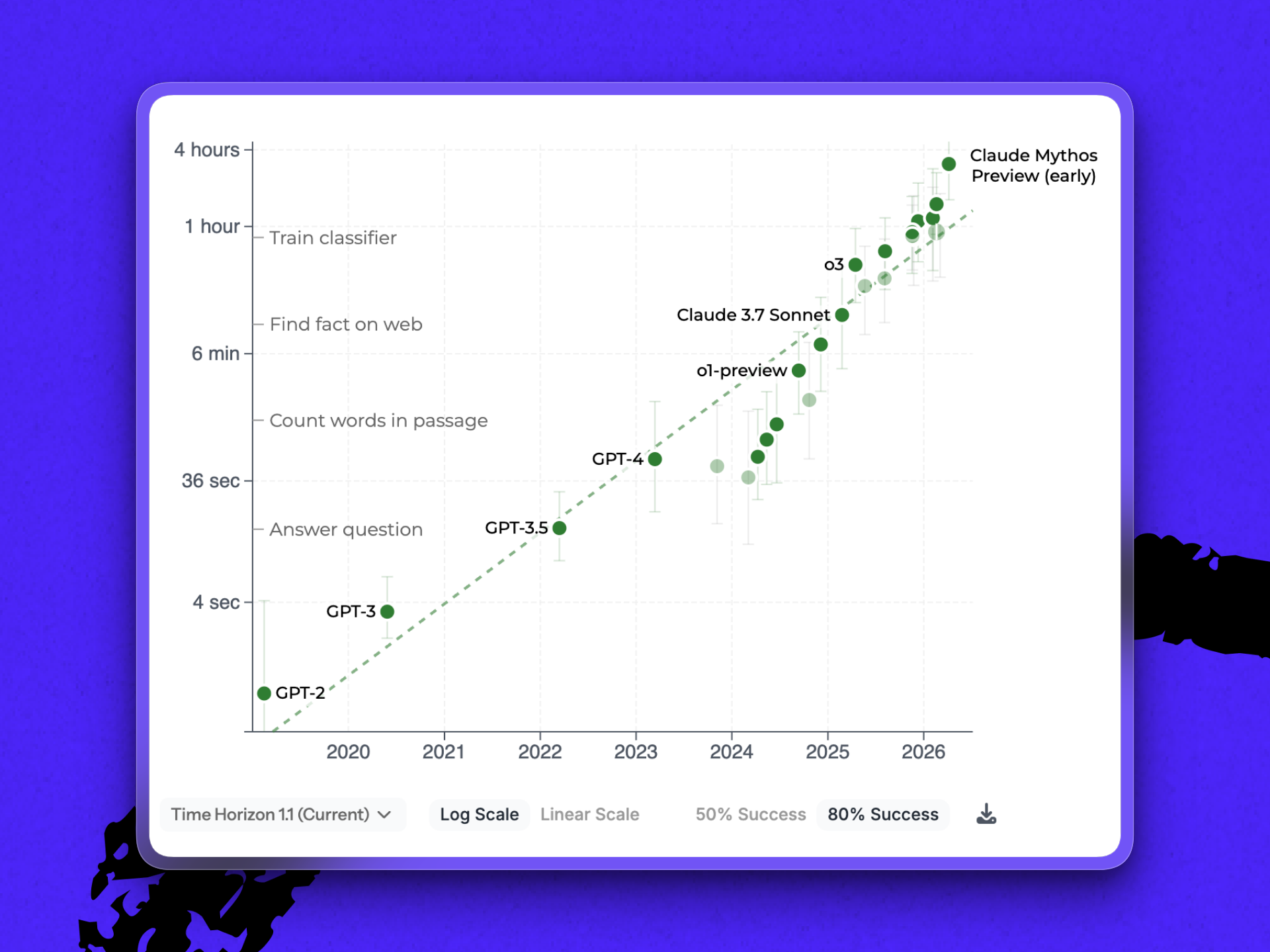
Both these things are true: Duration can be a useful proxy for difficulty, and benchmarks don’t reflect reality. “[They] don’t measure model capability alone,” says Dan. “They measure model capability after a human has done the work of finding a prompt that lets the model’s capability appear.”
What to do this week:
1. Figure out your longest agent run. METR teaches us that duration might be a good approximation of difficulty. Ask: What’s the longest stretch you’ve trusted an agent on autopilot? If you don’t know, you can’t extend it.
2. Extend your agent’s runtime by giving it a goal. Last month, OpenAI shipped a new /goals command in Codex that allows agents to pursue objectives across multiple turns without checking in. Yesterday, Anthropic introduced a similar command to the latest Claude Code version. Both are apt for long-running loops with clear criteria for success—and very much in line with what we’ve heard from Claude’s platform team. Try it out today.
3. Audit the effectiveness of your existing loops. If you already have agents running overnight, “How long did your agent run?” is still a useful diagnostic—but ask it alongside, “With what guardrails, against what feedback signal, and at what verified accuracy?”
Steal this workflow
Build your next agent skill like Perplexity does...
Become a paid subscriber to Every to unlock this piece and learn about:
- Perplexity’s rules for making durable agent skills
- Why voice AI changes office etiquette
- How Dan built an AI piano coach in a weekend
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.















Comments
Don't have an account? Sign up!