We use analytics and advertising tools by default. You can update this anytime.
Opus 4.8 tops both our Senior Engineer benchmark and our writing tests. It’s the most complete model we’ve tested. We just wish it had an app to match.
Anthropic is so back.
They’ve had the wind at their backs for the past year, riding the Claude Code wave into the rest of knowledge work. But Opus 4.7 was a hard-to-use, hard-to-love model, and the Codex desktop app is clean, fast, and feels like the future. I switched to Codex full time, and even Every’s most devoted Claude users like Kieran Klaassen and Katie Parrott found themselves reaching for GPT models in a way they hadn’t in at least a year.
But Opus 4.8 is a legitimately great model, jumping to the top of the pack in the rankings (and our hearts). It bests GPT-5.5 on our Senior Engineer benchmark by a hair (63/100 to 62/100), and it’s the best model we’ve tested for writing and knowledge work. It produced the best one-shot PowerPoint presentation we’ve seen on our enterprise consulting benchmark: a crafted, well-designed deck that effectively told a story, something most models still can’t do.
It’s very hard to make a model that is both an incredible software engineer and a near-human writer with depth and emotional intelligence—but that’s what this model feels like to us.
They could have called this Opus 5 and none of us would have blinked.
There are two catches. The first is that output quality is heavily dependent on effort level. Opus 4.8 at extra-high is a competitive senior engineer, while at high it’s an adequate one. Opus 4.8 at high delivers mostly clean, expressive prose, while Opus 4.8 at medium succumbs to AI’s worst writing tendencies.
Second, the model is better than the app around it. Opus 4.8 is strong enough to make us want to move back to Claude. But the Claude app is a mess. It has three different tabs—Chat, Code, Cowork—that bear the scars of the harness’s progression through time and Anthropic’s org chart. That makes the experience feel slow and messy, and it doesn’t allow us to easily get the most out of the model.
We get into all of this below.

Most outbound tools pull lists from external databases and generate sequences from generic prompts. They run from the outside in. Lightfield runs from the inside. The agents score accounts against your real won deals, draft sequences from your actual customer language, and source contacts with warm intro paths from your network.
You set the strategy. The agents build the list, run the sequences, and escalate the replies that need you. More than 3,000 startups on the platform.
Anthropic is positioning Opus 4.8 as a stronger model for complex work, especially coding, agentic tasks, and long-running reasoning.
At extra-high, Opus 4.8 scored 63 on our Senior Engineer Benchmark, a hair past GPT-5.5’s 62 and a 30-point jump over Opus 4.7. At high, it falls to 42.
Opus 4.8 at high effort scored 79.6 on our writing benchmark, ahead of Sonnet 4.6 (74.5), GPT-5.5 (73), and Opus 4.7 (63). It also left fewer AI tells than any model apart from Sonnet.
Faster than 4.7, better at explaining itself than GPT-5.5, and unusually good at adopting your voice from a style guide. But it hangs back and waits for instructions where GPT-5.5 runs ahead.
Big enough to hold an entire codebase, a book-length manuscript, or weeks of meeting notes in a single session, and it carries context across that span better than 4.7 did.
Opus 4.8 is good enough to pull us back to Claude, but the Chat/Code/Cowork split keeps Codex as the better daily harness.
“This is my favorite frontier model. Its performance is a major improvement over Opus 4.7 across coding, writing, knowledge work, and even psychology and interpersonal advice. It’s hard to improve a model across all those dimensions at once, which is why I think they should’ve rounded it up to Opus 5—calling it 4.8 undersells the jump. The catch: Codex is still, by far, a far better harness than the Claude Desktop app, and so GPT-5.5 remains my daily driver. But I’m now switching between Codex and Claude all the time.”
“Opus 4.8 is my favorite model right now. It feels deep without being overwhelming, and it communicates better than GPT-5.5 or Opus 4.7. Its work is readable and easier to follow across coding and product tasks. It’s slower than GPT-5.5 and sometimes too noisy in comments, but I’ve already moved some autonomous workflows from GPT-5.5 high to Opus 4.8 at extra-high because it performs well and feels less mechanical.”
“I lost a bit of trust in Anthropic after Opus 4.7. But Opus 4.8 is a model I can trust to get the work done, whatever it is. It’s a major quality-of-life update: more intuitive, easier to collaborate with, and better at carrying context and direction across a long session than Opus 4.7. GPT-5.5 is still faster, which makes it my go-to for iterative work, but Opus 4.8 has the brains and the personality to make me want to stick with it for code and copy.”
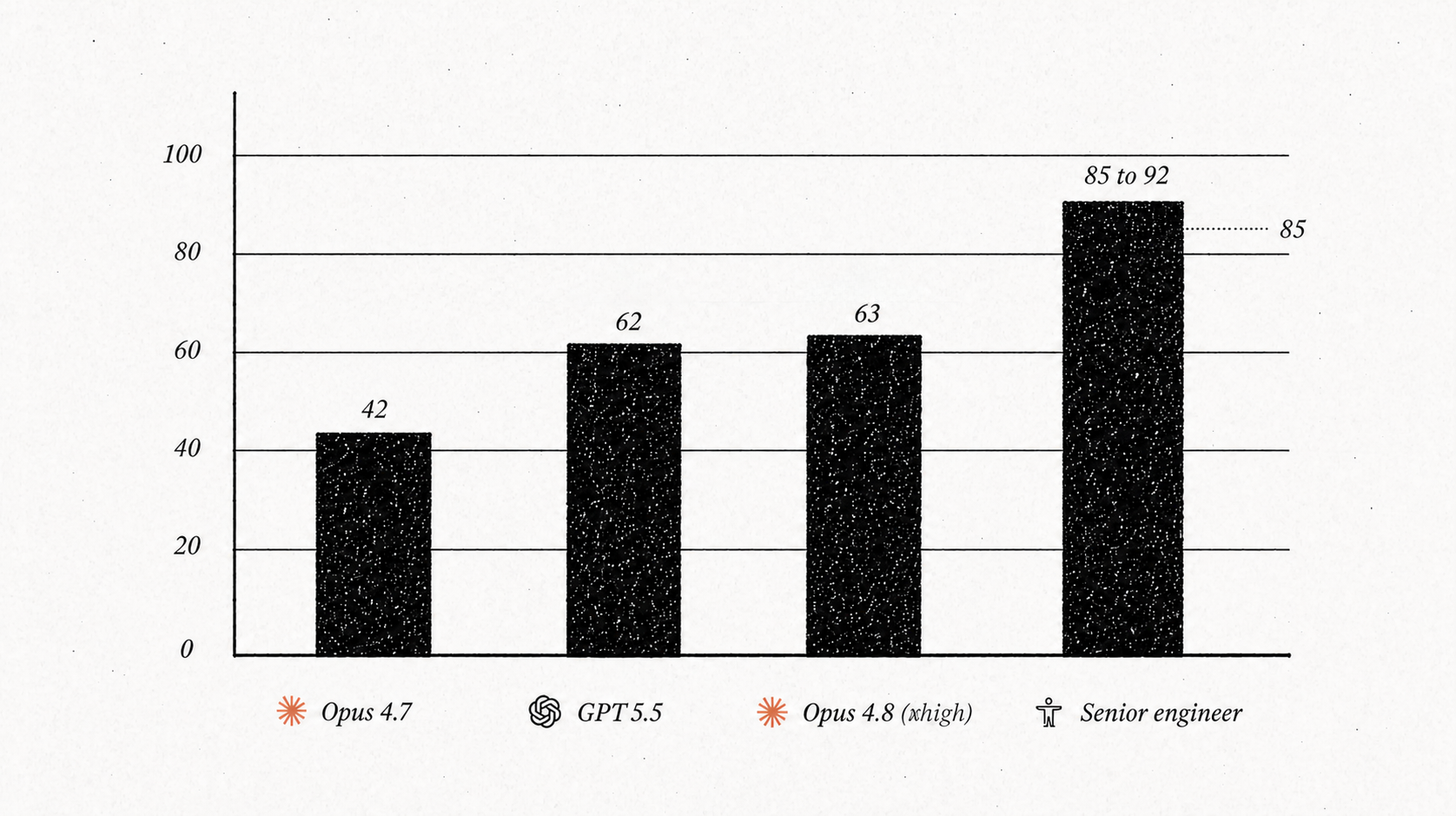
At extra-high, Opus 4.8 bests GPT-5.5 on the hardest engineering test we run—it scored a 63 on this benchmark to GPT-5.5’s 62. It also ranked first of the three models we compared on readable Ruby code.
The Senior Engineer benchmark gives models a real, messy, vibe coded codebase and asks it to do what a senior engineer would: Rewrite it from scratch.
Opus 4.8’s score depends on the effort setting. At high, it scored 42. It was only able to patch the surface-level problems in the codebase, and avoided doing the architectural rewrite.
At extra-high, Opus 4.8 scored 63—30 points better than 4.7—and just a hair better than GPT-5.5. This time it built a genuine replacement for the core app and provided a safe way to transition over to it—while staying honest about what it left unfinished. “The jump is about courage rather than more thinking,” Dan says: At high, Opus 4.8 nibbles around the edges the way Opus 4.7 would. At extra-high, it will change the shape of the system if it has to.
Opus 4.8 at high effort vs. extra-high
Opus 4.8 and GPT-5.5’s best on the benchmark
Opus 4.7’s score on the same test
The two human senior engineers
Despite its impressive score, Opus 4.8 still has some rough edges on this benchmark. Even at extra-high, it sometimes calls a job “weeks of work” when it should only take a few hours. Below extra-high, you get a careful fixer rather than an architect. Anthropic told us it is looking into this behavior and pointed us to a “Max” setting for the hardest problems.
Opus 4.8 beats GPT-5.5 on code you’d want to inherit—the kind a human can read and maintain later. When generating readable Ruby code, Kieran ranked it first of three; his shorthand is that GPT-5.5 is the eager, brilliant 25-year-old, Opus 4.7 the cocky professional, and Opus 4.8 “the 50-year-old that has seen the world, and just delivers.” Models often hand back everything they can think of and leave you to delete half on the next pass. Opus 4.8 “goes deep, then thinks about how to shape or deliver what it found instead of just giving it all,” Kieran said. “Depth without the overwhelm.”
The eager, brilliant 25-year-old
The cocky professional
The 50-year-old that has seen the world, and just delivers
The same restraint shows in how it plans. On LFGBench—Kieran’s benchmark for building a working product end to end, from interface to server logic to design—Opus 4.8 laid out its plan in plain prose and explained its judgment calls, whereas GPT-5.5 wrote a terse checklist that’s harder to vet or hand to someone else. The finished work followed the effort curve again: On a build called cozy-island-3d, which tests the model’s ability to render a 3D landscape, Opus 4.8 scored 84 at high, behind Opus 4.7’s 89 and GPT-5.5’s 92, then jumped to 97 at extra-high.

Opus 4.8 also uses fewer tokens—the units of text a model reads and writes, and what you pay for—than GPT-5.5 or Opus 4.7 on the same job, though it runs slower: GPT-5.5 is two to three times faster.
At high effort, Opus 4.8 is the best writer we’ve tested. But the current Sonnet, 4.6 is right behind it, and the effort setting makes or breaks the result.
For this Vibe Check, we designed a set of writing challenges based on the editorial jobs we ask a model to do: Draft an introduction from scratch, write a promotional email, insert a missing paragraph in the middle of a piece, and anticipate the edits our human editors might make. Every model got the same eight assignments and never saw the published version, which we use as the gold standard. Each result ran through the same editing checks we apply to our own writing, and an independent AI graded each output without knowing which model wrote it. We measured two outcomes: overall quality out of 100 and a count of “AI tells”—the giveaways that a machine wrote it.
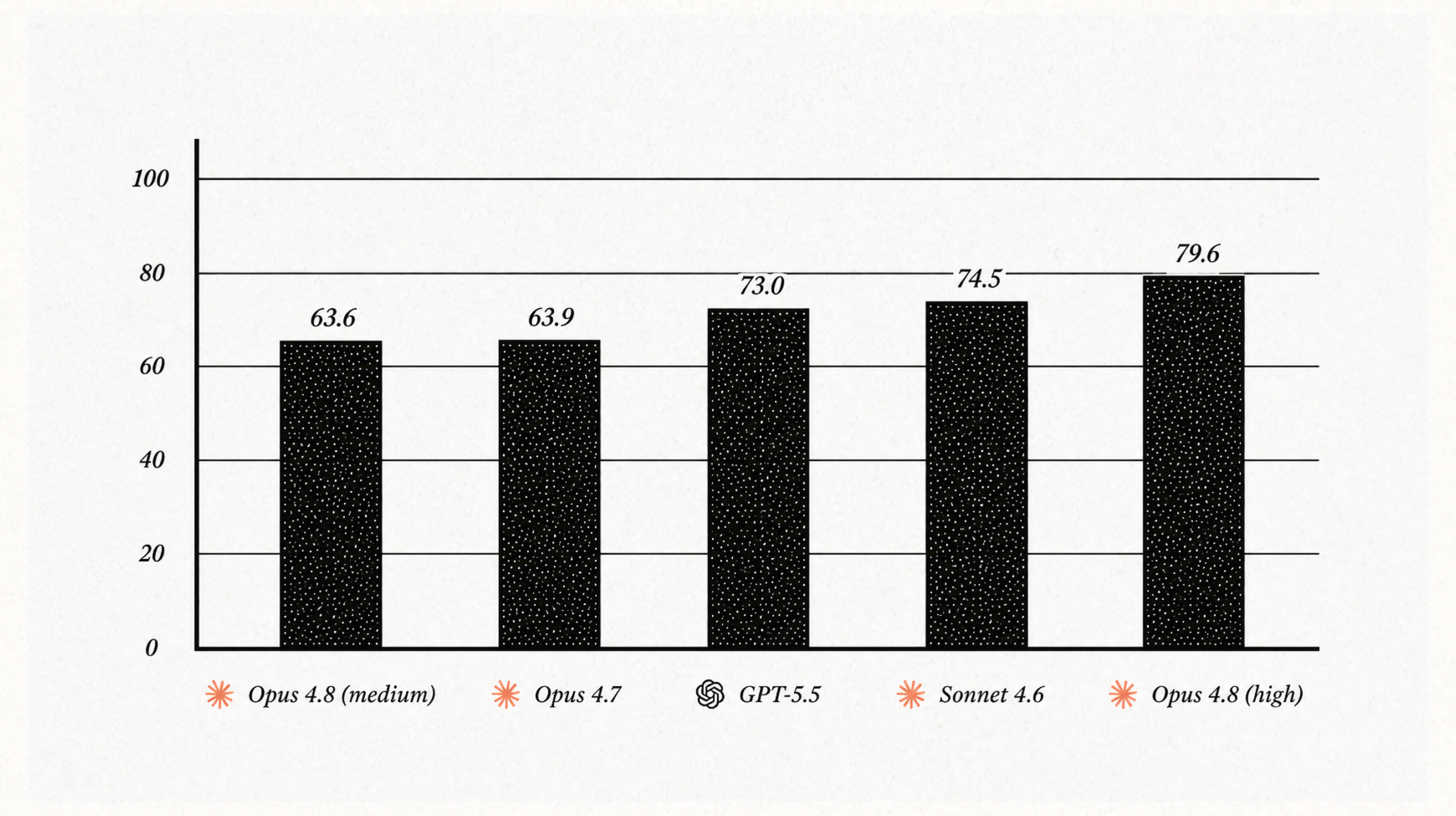
Opus 4.8 at high effort scored highest, at 79.6. But the runner-up is also Claude: the current Sonnet 4.6, at 74.5. GPT-5.5 lands third at 73, with Opus 4.7 well back at 63. So Opus 4.8 wins, but mostly against its own family, and only by five points over a Sonnet we already had.

“AI smell” remains a challenge for Opus 4.8, though less than for most models we tested. Opus 4.8 left 13 tells across eight tasks—comfortably under GPT-5.5’s 21 and Opus 4.7’s 25, but more than double Sonnet 4.6’s six. Opus 4.8’s chief offender is one no lab has trained out yet: the negative parallelism of “it’s not X, it’s Y.” It shows up less at high effort than at medium, but it’s there. We caught several while drafting this piece, which we wrote with Opus 4.8.
One thing Opus 4.8 does well is absorb a writer’s voice from context. Katie pointed it at two of her own style guides—a flowery one for personal essays and a more conversational one for her Every column—and it picked up the difference between them and produced writing that matched each style. “It’s a bit like tofu,” is how Katie put it. “It’s all in the flavor of the sauce.”

Human-level editing is one task no model we’ve tested, including Opus 4.8, has cracked. We took an essay our editor-in-chief Kate Lee had already marked up and asked each model to make the same calls she did. Opus 4.8 caught 5 of her 14 changes and scored 22; every model we tested landed somewhere between 11 and 23. They can spot bad writing—handed a passage deliberately seeded with AI tells, Opus 4.8 caught all 12—but on this test, they still couldn’t tell what to cut from good writing to make it great.
Opus 4.8 is an excellent everyday work partner. It’s faster than Opus 4.7, can anticipate your needs, and is unusually good at explaining itself in terms a non-technical person can understand. However, in our open-ended research test, it was more conservative and literal than GPT-5.5, and it’s confidently wrong just often enough to keep you checking. Asked to retrieve Katie’s recent essay on AI and entry level jobs, it came back with one almost a year old instead. Opus 4.7 made the mistake, though, so this is more of a reminder to keep a skeptical eye on your model’s responses than a model-specific indictment.
The first thing you notice is the speed. Opus 4.7 was slow enough that you’d kick off a task and walk away. With Opus 4.8, you can sit down and watch it work without losing patience. It also decides how hard to think on its own, based on how complex it judges the task to be. It’s not as quick as GPT-5.5, but as Kieran said, it’s far nicer to work with than 4.7.
It’s also impressively versatile, moving between types of work even within one conversation. Katie had it build an agent-native application for her website, then started to write a post based on what was in that application. Opus 4.8 noticed her working draft had drifted out of sync with what was in the code, flagged the disparity, and offered to fix the parts of her app that depended on it—fact-checking and coding in one thread, neither of which she asked for.
Opus 4.8 can be overeager to help: It ends nearly every response with a short menu of suggested next steps. What it tends not to do is act without your go-ahead. Where OpenAI’s models often took initiative in our tests, Opus 4.8 hung back and waited for the go-ahead. Katie gave both Opus 4.8 and GPT-5.5 the same assignment to research AI’s effect on jobs. GPT-5.5 in Codex returned quotes, counterpoints, and angles we hadn’t asked for; Opus 4.8 stayed closer to the prompt.
Every’s head of technology consulting, Mike Taylor, ran Opus 4.8 on his Consulting Benchmark consisting of 10 real-world consulting tasks. He found that it was the best model he’s seen so far on this benchmark, consistently producing results with depth, taste, and discernment.
In particular, it did the best on PowerPoint generation. Opus 4.7 was already very strong on deck content, but Opus 4.8 added more depth to the topic. Previous models have been too shallow.

Mike also asked Opus 4.8 to choose topics for AI training sessions based on call notes with potential clients. Opus 4.8 produced spiky results: It had a few really great ideas and a few suggestions that could be thrown away. But that’s exactly what Mike wants when he’s co-working with an agent—he wants the agent to push his brain in new and interesting ways. GPT-5.5 rarely makes a mistake, but it also rarely produces a “banger” in his opinion.
Anthropic’s product carries its history in its architecture. Chat, Code, and Cowork are separate rooms you walk between; Codex feels like one place where work starts and finishes. So practically speaking, our workflow this week was hybrid: Codex stayed home base because its harness is better, but Opus 4.8 was good enough that we kept flipping back into Claude—or pulling it in as a subagent—because the model was too useful to leave on the shelf.
It’s worth distinguishing model problems from app problems. The friction we hit—roughly a second of typing latency in the Claude Code app, local server links opening in Chrome instead of in-app, stale worktree and merged-PR bars, extra-high initially not being selectable in the app—is product-level friction, not model behavior. (And early-access latency is explicitly not production latency.) None of it is a knock on Opus 4.8. But the Claude app isn’t Codex-caliber yet.
Opus 4.7 felt like a big model: slower, more literal, sharp at the edges, and high-maintenance about it. Opus 4.8 is the opposite kind of upgrade. It’s fast, readable, and easy to collaborate with, and it’s the first Anthropic model that credibly does code, writing, and everyday work all at once—at the right effort. It became a model the team kept reaching for over a single weekend.
You’ve been juggling one model for prose and another for code.
This is the first we’ve tested that does both well. Adopt it now for writing and everyday work; for serious engineering, run it at extra-high—that’s where it shines.
You want a strong, on-voice first draft.
It topped our writing benchmark at high effort and takes direction on voice better than anything we’ve tested. Run it at high and remember to bring your own style guide.
You’re doing serious work on a mature codebase.
At extra-high, it found the right architecture on our hardest rewrite test and beat GPT-5.5’s best, provisionally 63 to 62. It still needs review—and occasional cajoling—but the gap has reversed.
You’re not technical and want a guide, not a black box.
Opus 4.8 explains itself clearly without condescension.
You gain speed, concision, readability, better-tuned thinking, materially better writing, token efficiency, and more willingness to act.
You gain fewer AI tells and a better ear for voice—and, at extra-high, the hardest code rewrites too (provisionally 74 to 62.5). You give up some initiative and the better app.
For a frontier model, Opus 4.8’s pitch is unusually grounded: not the flashiest output, but the one you’d actually keep reaching for. It’s strong enough to make us want to go all in—as soon as Anthropic fixes that app.
Dan Shipper is the cofounder and CEO of Every, where he writes the Chain of Thought column and hosts the podcast AI & I. You can follow him on X at @danshipper and on LinkedIn.
Katie Parrott is a staff writer at Every. You can read more of her work in her newsletter.





