
I Stopped Writing Code. My Productivity Exploded.
Why giving up manual coding made me more valuable, not less
Jun 20, 2025Updated Feb 2, 2026
Sparkle is a special product at Every. It’s been owned by four different people and rebuilt four times. But this version is different: Today we’re releasing file de-duplication, a feature built on top of what we know and love Sparkle to be. Tens of thousands of people love Sparkle’s organization features—you're going to love de-dupe, too. It’s the fastest and most accurate way to reclaim space on your computer.—Brandon Gell
Six months ago, I wrote almost every line of code myself. Today, I haven't typed a function in weeks—and I recently found 158,000 duplicate files on my desktop without writing a single line of code to do it.
The transformation happened while I was building the latest feature for Sparkle, our AI-powered file manager. Users kept asking: "Can you detect duplicates? I'll pay extra for it." We all have them: that presentation you downloaded three times because you couldn't find it. Screenshots of the same thing from different days. Email attachments you save "just to be safe." I'd been dismissing the requests—Sparkle was for AI-powered file organization, not cleanup—but they kept coming.
In the meantime, I had begun to question my value as a developer. I used to solve coding problems like sudoku puzzles; now I was watching Claude solve them while I just supervised. The brain rot was real, and I was terrified.
The irony was perfect: Here I was, worried about becoming redundant. Why not build a redundancy finder?
Then Reid Hoffman's advice echoed in my head: "Run more agents." So with this project, I decided to lean into it completely: pure AI agents, no fallback coding, no writing functions when things got tough.
Three weeks later, I wasn't thinking about it as outsourcing code anymore. I was building at the speed of thought. In the process, I'd become something different. Traditional developers write code. Agentic developers direct AI to write it for them. They focus on what to build and why, while AI handles the how. That fear of becoming obsolete? I had it backward.
How we built the duplicate finder
I opened Claude Code with a simple question: "If you had 10,000 files, how would you find which ones are duplicates?"
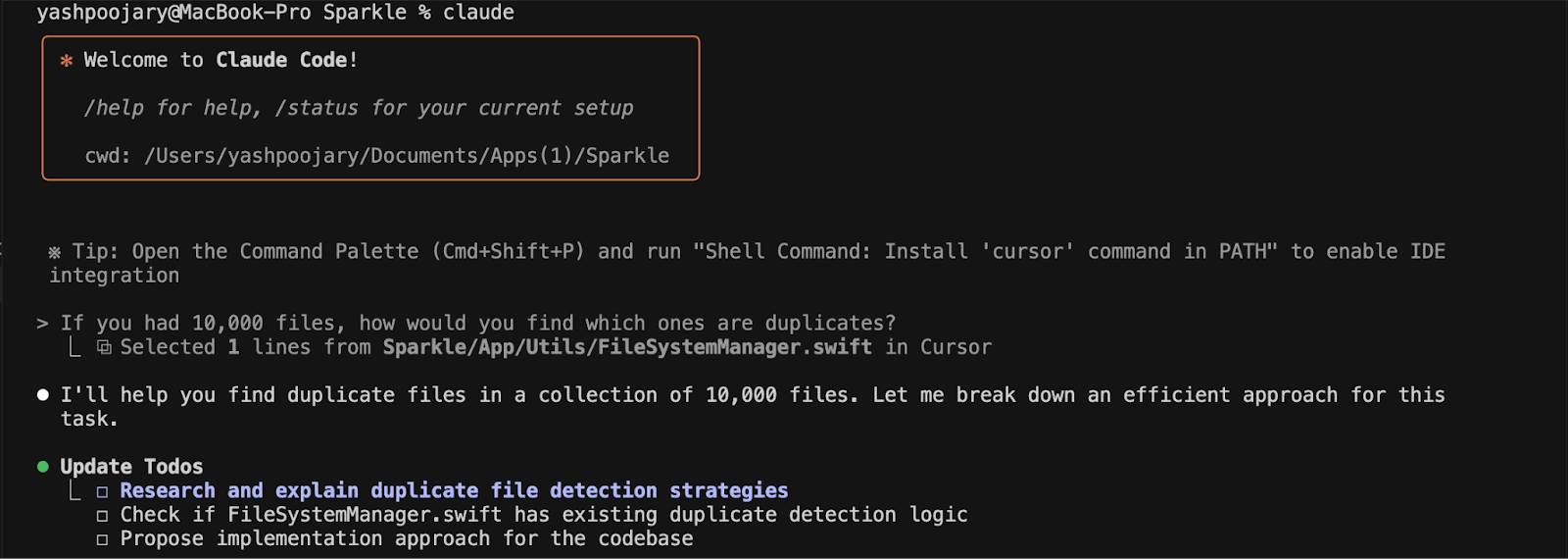
You might think that you’d find duplicates by comparing file names. But names are meaningless—"Report.pdf" and "Report_final_v2.pdf" could be identical files. What matters is content. Claude took a logical approach: Check the easy stuff first (file size) before the hard stuff (content).
If you compared every file to every other—file 1 against the other 9,999, file 2 against the other 9,998, and so on—that’s nearly 50 million operations. Your computer would crash. But if you group them by size first, most files get eliminated immediately. They have unique sizes, so they can't have duplicates. That narrowed down the amount of potential duplicates to about 100.
From there, it started listing approaches it could take: hash-based detection, command-line tools, specialized software. But I stopped it. "Don't write any code yet. Let's think through this problem together." This instruction helped. Instead of jumping straight to code, we talked through the problem first.
Three stages of file de-duplication
Working in Claude Code’s terminal window—with no fonts or UI and just text—felt weird at first, but that simplicity forced focus. Through 15 minutes of back-and-forth, we refined the approach:
Stage 1: Size grouping
Group all files by exact size. If a 2.3MB file is the only one of that size, it has no duplicates and requires no further checking.
Stage 2: The peek test
For those files sharing sizes, read just the first 16KB. Files that differ in their opening can't be identical. Why read gigabytes when 16KB tells you enough?
Stage 3: Fingerprinting
For the files that passed both filters, we used hashing. Think of hashing like digital fingerprinting. It reads your entire file and generates a unique code. The same file always produces the same code, but if you change even one bit, the fingerprint completely changes.
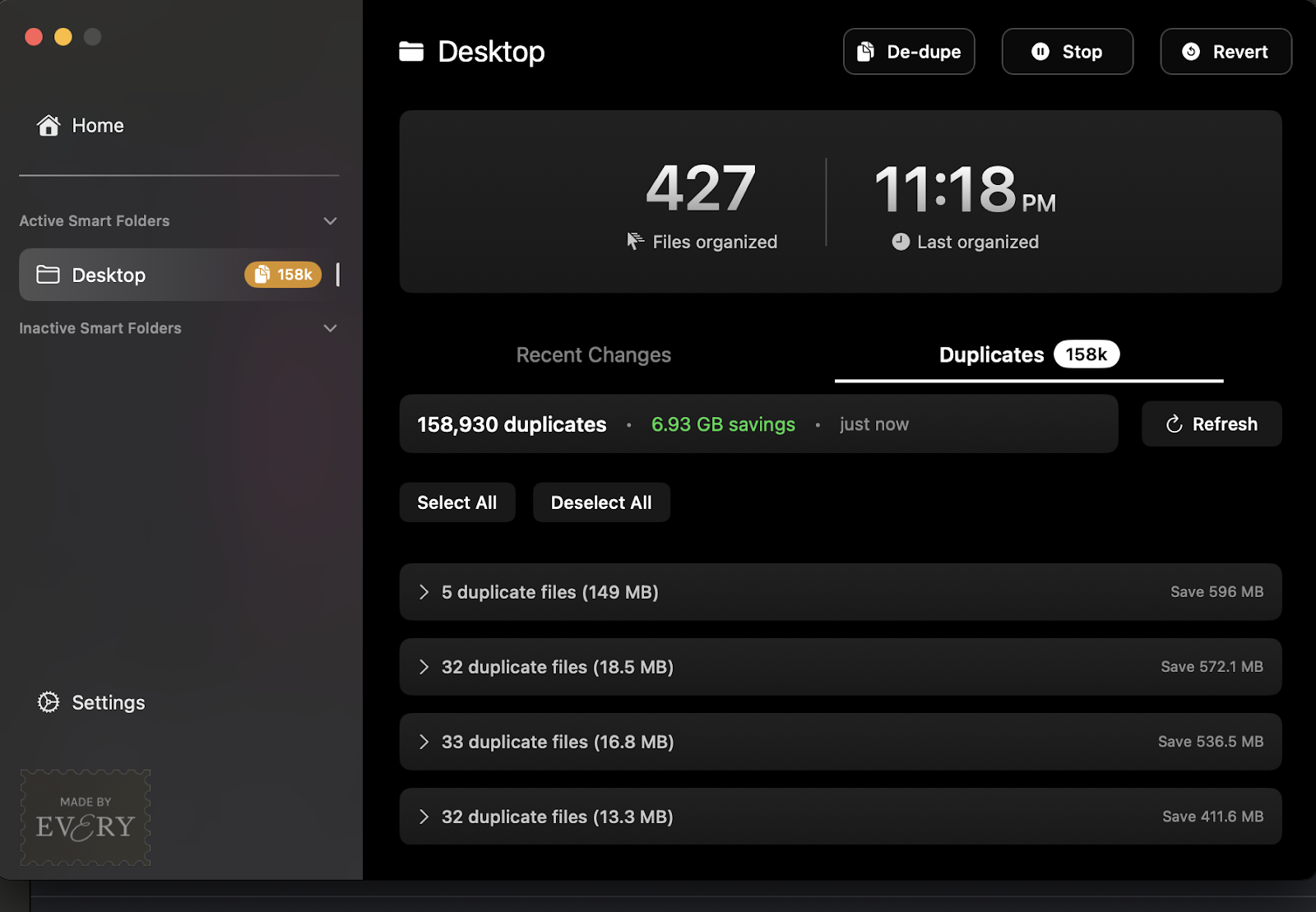
Using this three-stage approach, we went from 50 million operations down to about 10,000 operations—a 99.98 percent reduction in work. When I ran it on my own desktop, I found those 158,000 duplicate files. It was the best code I’d ever “written.”
Shifting from doing to directing
I didn't ask any coding questions...
Become a paid subscriber to Every to unlock this piece and learn about:
- The issues that Yash focused on in lieu of writing code
- Four tips to thriving as an agentic developer
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in.
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools






 Front-row access to the future of AI
Front-row access to the future of AI Bundle of AI software
Bundle of AI software





Comments
Don't have an account? Sign up!