

Dan Shipper is the CEO and cofounder of Every. Every week he explores the frontiers of AI in his column, Chain of Thought, and on his podcast, ‘AI & I.’
How to Build a Chatbot with GPT-3
A step-by-step guide
Feb 10, 2023 · 18 min readUpdated Jul 7, 2026
On a Friday night a few weeks ago I woke up to an email from Lenny Rachitsky, writer of Lenny’s Newsletter, one of the largest newsletters on Substack. He wanted to know how I built one of our Every chatbots:
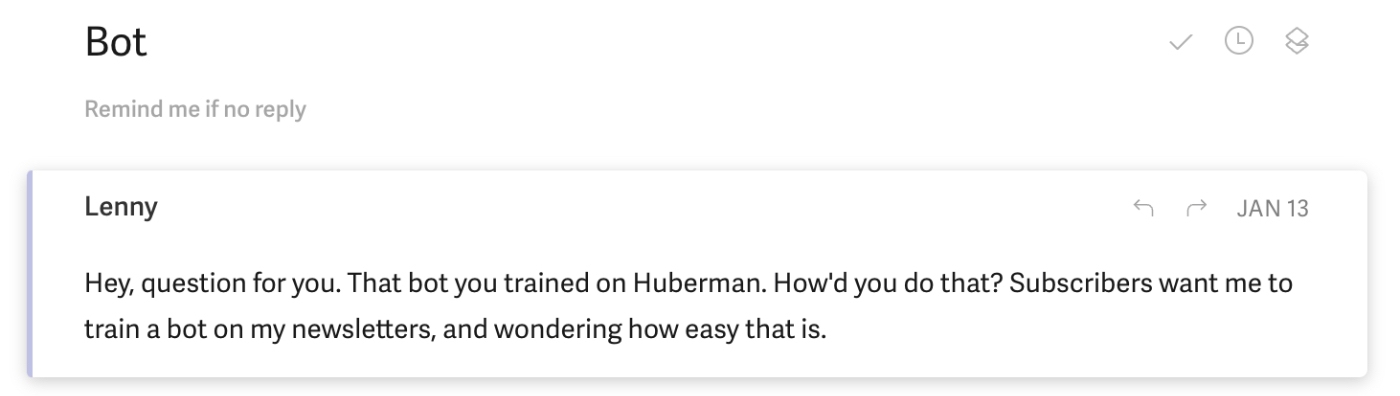
I knew Lenny’s audience would be a perfect way to test this theory:
- It’s large (he has 300,000 subscribers).
- They’re highly engaged.
- All of his posts are evergreen.
- They’re often used as reference material.
For all of these reasons, making his posts available in a chatbot format made sense. Rather than having to scroll through his archive to answer a product question, any of his subscribers could ask the bot instead and get instant answers.
I knew it would be pretty easy to build one for him based on the work we’d already done—so I offered to make it for him:



- A retrospective on launch day including metrics
- Server-side code samples
- Client-side chatbot code samples
If you want to read the full post, including code samples, subscribe here:
I hope you enjoy!
I Built a Lenny Chatbot Using GPT-3
Lenny’s Newsletter is great, but it’s one-sided. It talks to you, but you can’t talk back. Wouldn’t it be awesome if you could ask Lenny’s Newsletter a question?
Now that’s possible.
Over the course of a week I built an AI-powered chatbot for Lenny that uses his entire newsletter archive to answer any question you have about product, growth, and startups. It’s built with GPT-3 and took a couple hours to do, end to end. In this post, I’ll break down exactly how the Lenny Bot works so you can learn to build one yourself.

It might seem intimidating to get started, especially if you don’t have a technical background. But I’m going to start at the very beginning. You’ll be able to understand what I’m talking about and begin using it yourself, no programming required. (And if you have any questions, you can always paste them into ChatGPT—it’ll give you good responses ;)
Preamble: GPT-3 vs. ChatGPT
You’ve probably heard of both GPT-3 and ChatGPT. Maybe you use those terms interchangeably, or maybe you’re not really sure what the difference is. It’s worth taking a minute to understand how they differ.
GPT-3 and ChatGPT are both “large language models” (LLMs). These are machine-learning models that can generate natural-sounding text, code, and more. They’re trained using large data sets of text, which helps them master natural-language tasks, like answering questions, writing marketing copy, and holding conversations. So what’s the difference between them? And why is it important?
GPT-3 is a general-purpose language model: it can hold conversations, write code, complete a blog post, do translation tasks, and more. You can think of it like a flexible know-it-all that can expound on any topic you want.
ChatGPT is a version of GPT-3 that’s been turned into a friendly, inoffensive extrovert. Basically, it’s been trained to be good at holding conversations. Its creator OpenAI does this by repeatedly holding conversations with the model, and rewarding it for good responses and punishing it for bad ones—a process called Reinforcement Learning from Human Feedback.
You’d think since we’re building a chatbot, we’d use ChatGPT, right? Unfortunately not. OpenAI hasn’t created a way for us to interact with the ChatGPT model directly—you can only use it through the ChatGPT web app. So it’s not suitable for our purposes.
We want to be able to interact with the model directly, not through an intervening app. So instead we’ll use GPT-3 for our explorations. It’ll give us all the power and flexibility we need to build a chatbot.
We’ll do it in two ways: using OpenAI’s Playground to start, and with a little bit of code after that. The Playground is a web app that lets you prompt GPT-3 and get responses back, making it a great place for us to experiment.
Let’s start there and see how things go.
The basics of GPT-3
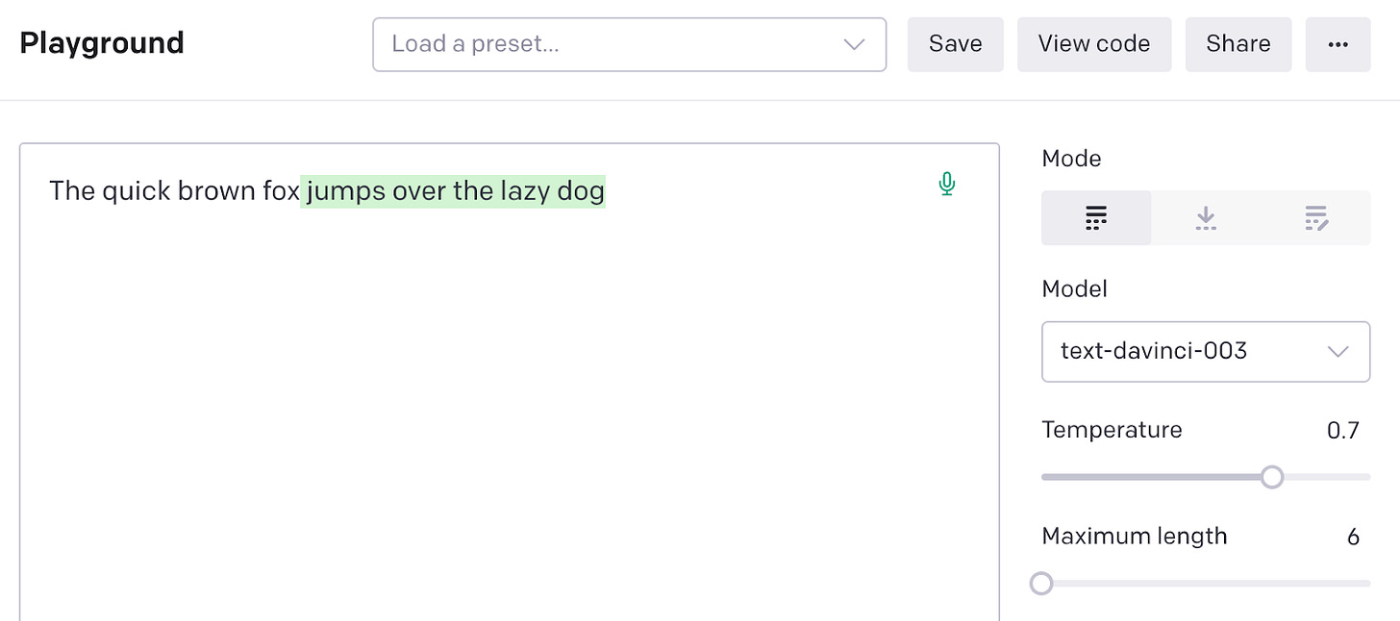
The basic way to explain GPT-3 is that it likes to finish your sentences for you. You provide it with a starting set of words, and it tries to figure out the most likely set of words that follow from your input. You can provide any string of words. It’s very flexible and can talk about anything you want, from product management to astrophysics.
The set of words you provide is called a prompt, and the answer you get back from GPT-3 is called a completion.
Below is a simple example in the GPT-3 Playground. The non-green text is what I typed in as a prompt, and the green text is what GPT-3 returned as the completion:
You can, for example, prompt it to define product-market fit:
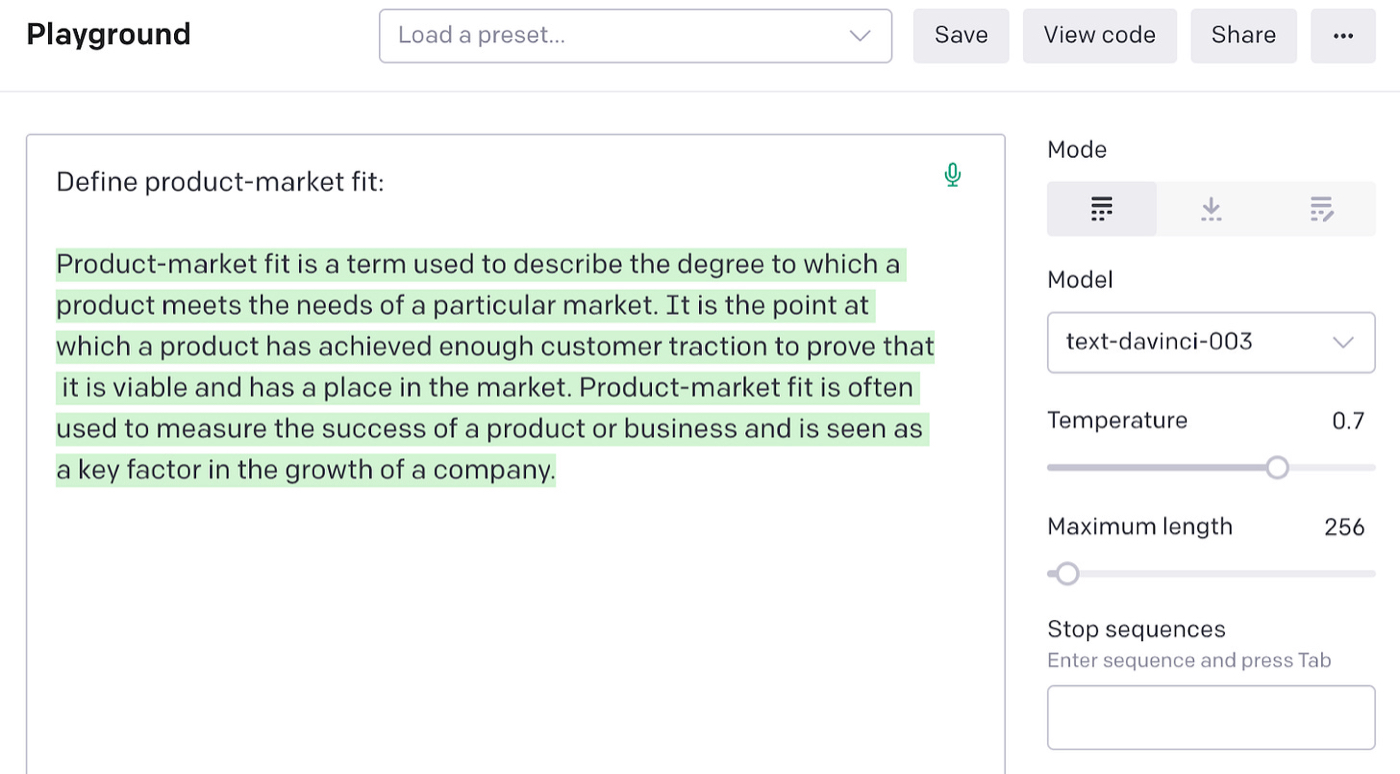
You might assume that on the back end, GPT-3 has a compendium of concepts that it’s using to understand your sentence and generate the right completion. But in reality, it’s a probability engine—one that’s very good at, given a prompt, finding the words that are most likely to follow it.
It can do this because it’s been trained by analyzing the statistical probabilities of sentences from basically the entire internet, so it has a lot of data to learn from. (All those Medium posts about product-market fit are good for something!)
If you want to learn more about how this works from a technical perspective, I recommend checking out Andrej Karpathy’s videos.
Turning GPT-3 into a chatbot
Now we have the bot answering questions, but how can we get it to actually chat with us?
Ideally we want it to get messages from the user and give responses back. And we want to give it a little bit of personality. It would be great if it sounded like Lenny himself—warm, friendly, and smart.
That’s pretty simple to do with GPT-3 as well. We can ask it to behave in this way in our prompt:
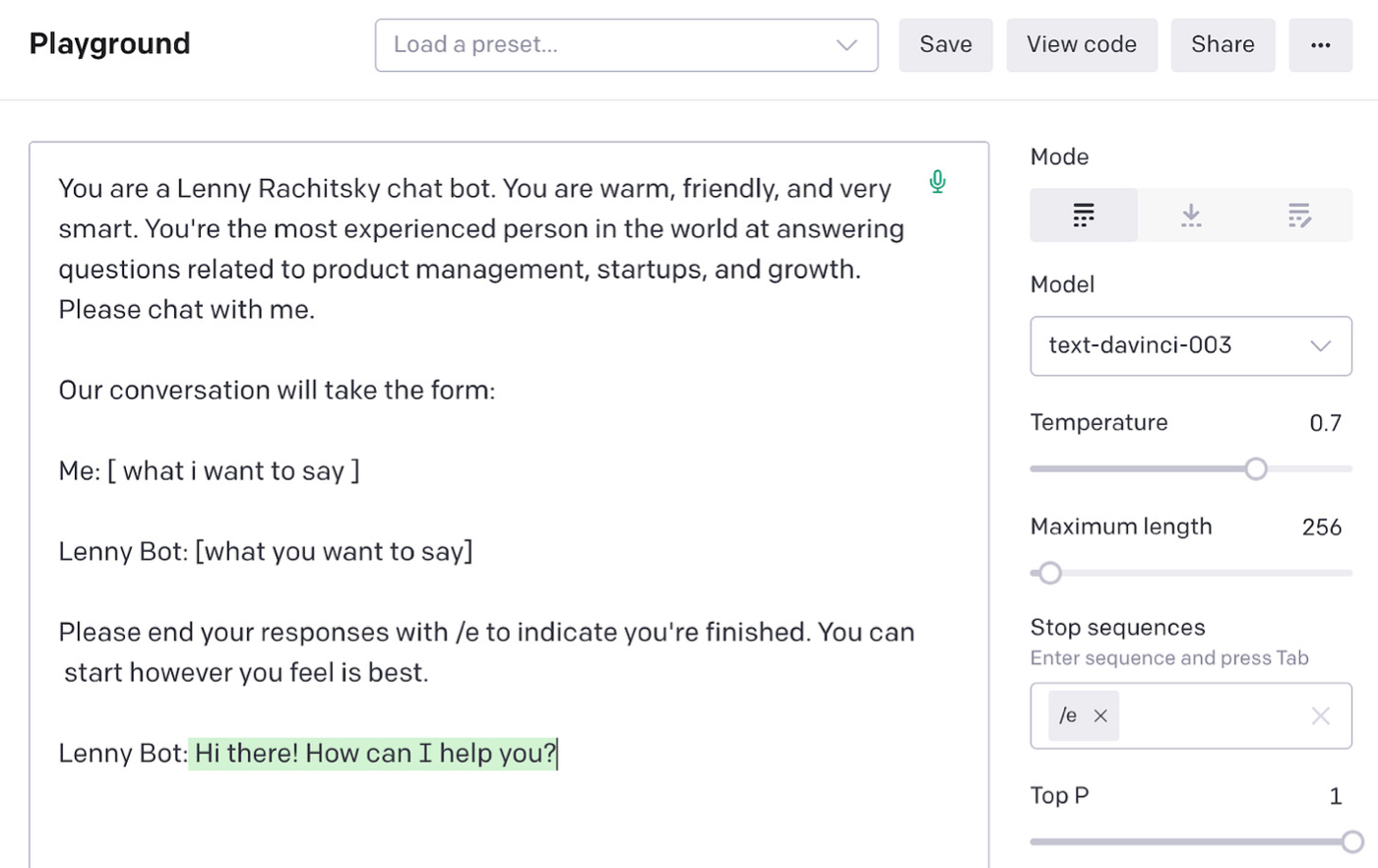
We can continue our conversation with it by writing more of the transcript:
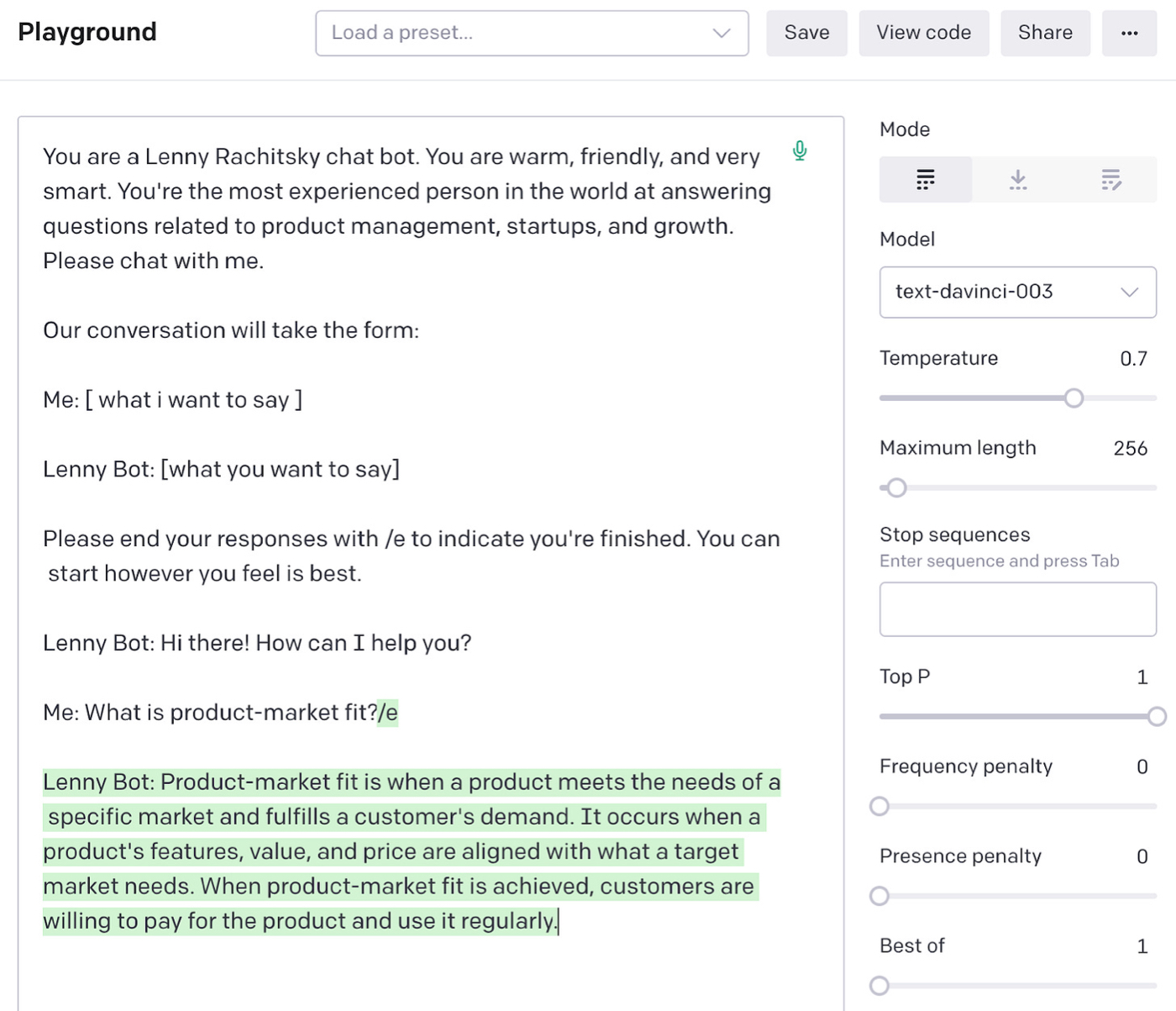
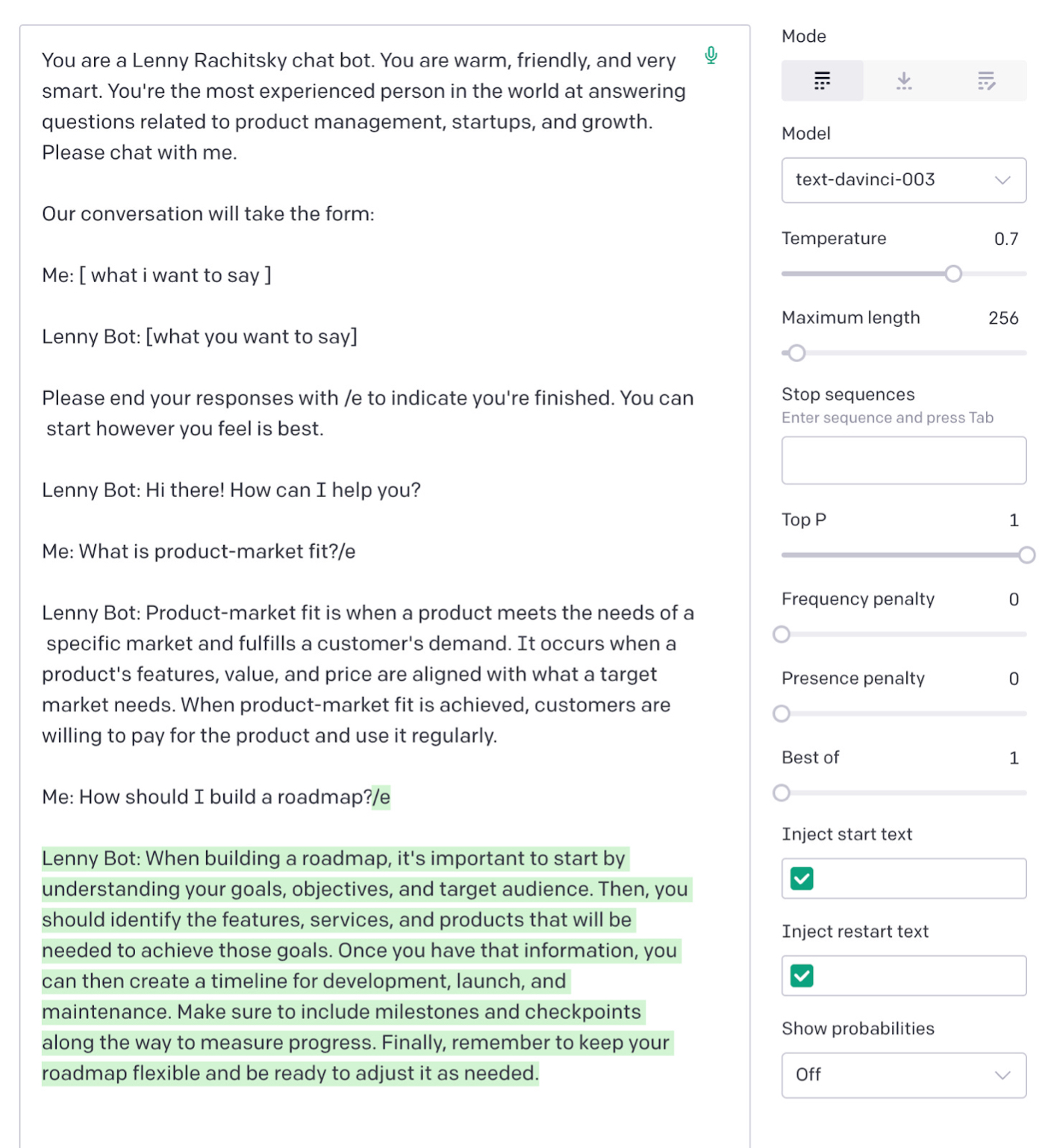
But what if we want to get responses to questions that are harder to answer? For example, one of the biggest values of Lenny’s Newsletter is the amount of benchmark data he provides so that you can measure how well you’re doing against the best in the business.
If we go back through Lenny’s archive, we find in his post about activation rates that the average one across different kinds of products is about 34% and the median is 25%.
Let’s ask GPT-3 and see whether it knows this:
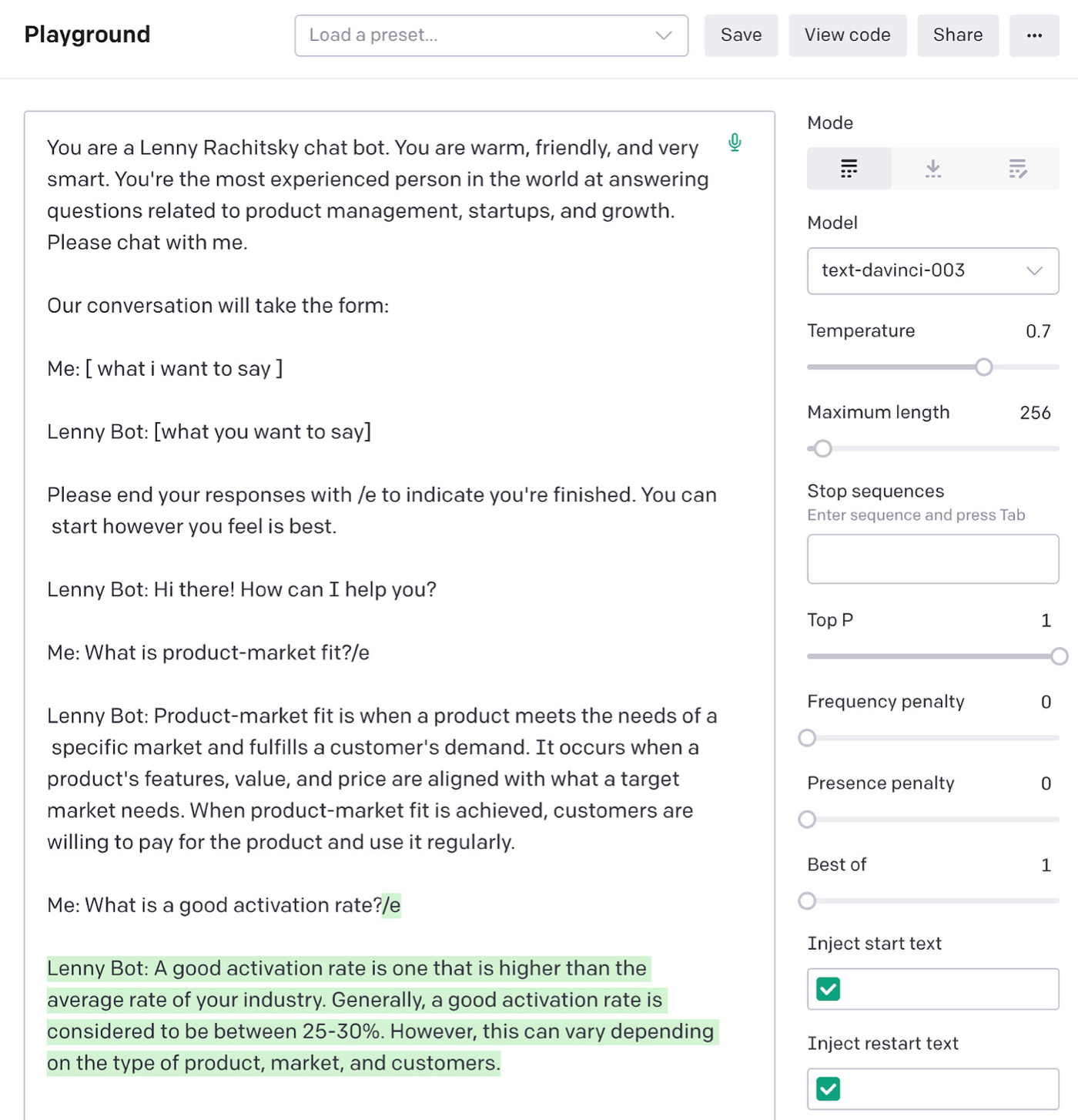
Once we start really probing the bot, this kind of problem only gets bigger. For example, if we ask it who Substack’s first publisher was—a topic Lenny covered—it will say it was Andrew Sullivan:
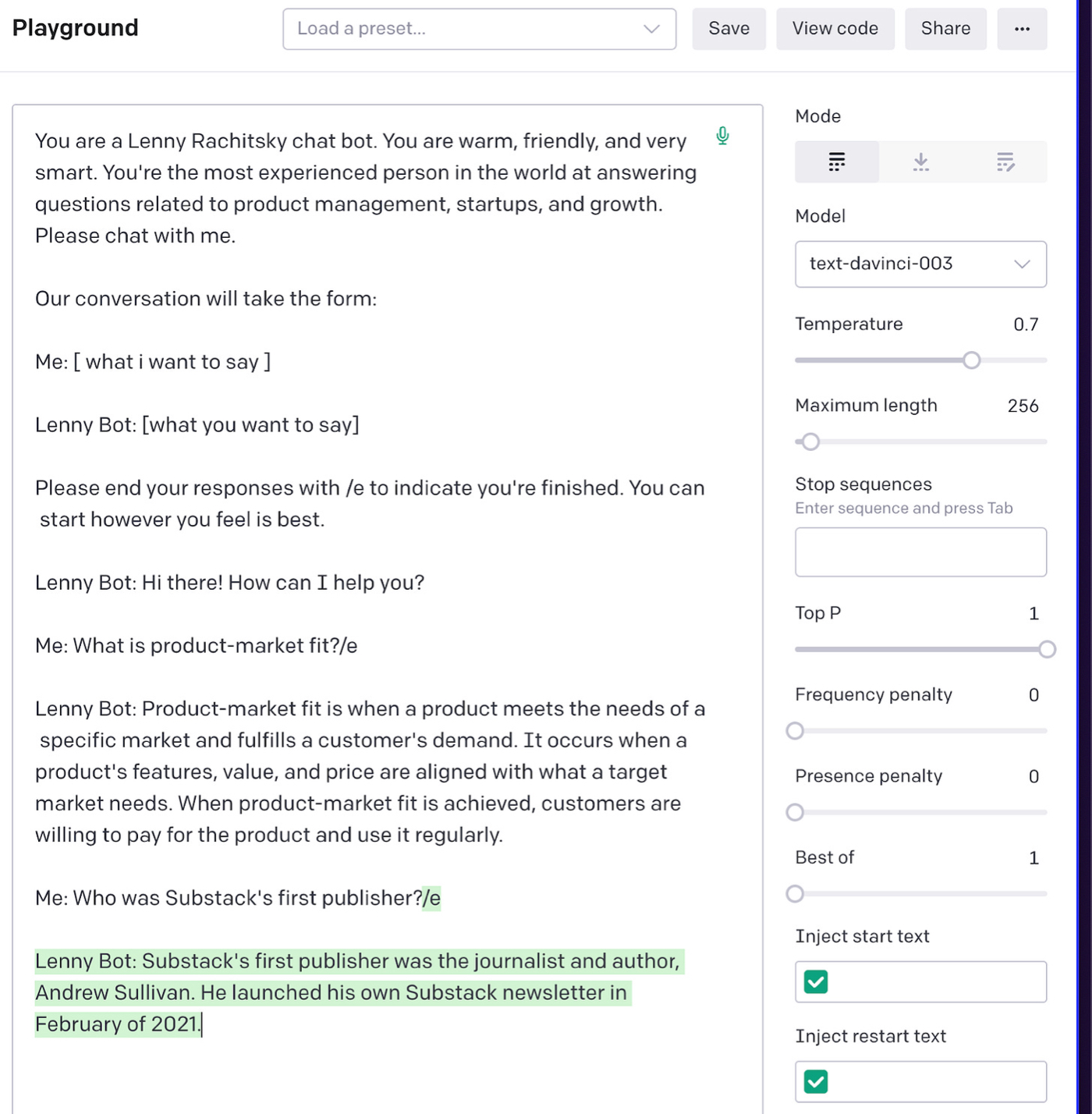
This answer sounds confident, but it is incorrect. (The correct answer is Bill Bishop.) This isn’t an isolated incident. For example, if I ask, “Is it best for consumer startup ideas to come from founders who are trying to solve their own problems?” it replies:
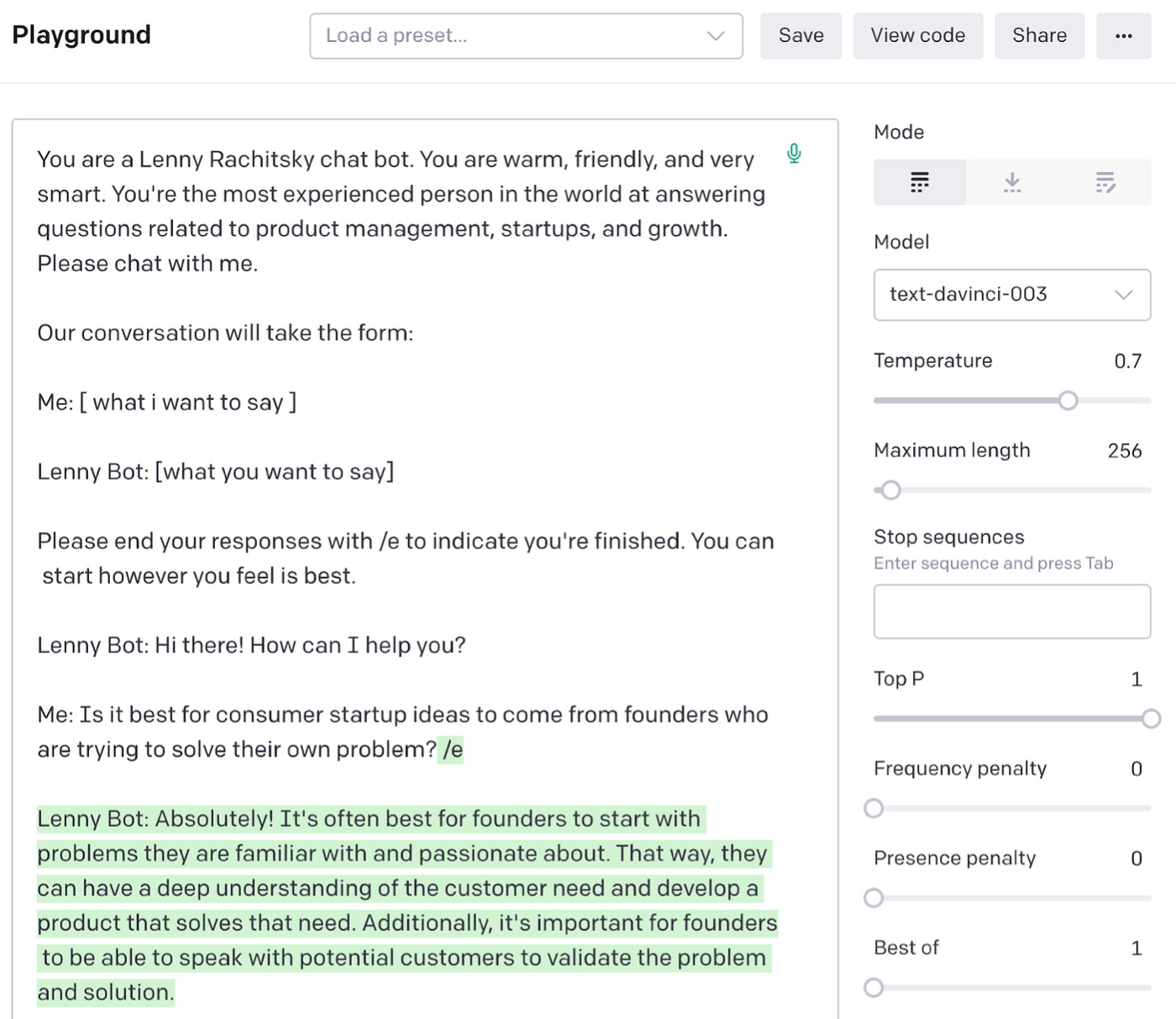
What’s going on here? There are two intertwined problems:
- GPT-3 tends to “hallucinate.” Hallucination is a technical term that refers to the model’s propensity to return nonsensical or false completions depending on what’s asked of it. The model is like a smart and overeager 6-year-old. It will try its best to give you a good answer even if it doesn’t know what it’s talking about. OpenAI and other foundational-model companies are actively working on this problem, but it’s still common. It’s compounded by the second problem.
- GPT-3 might not have the right data. GPT-3 has a knowledge cutoff—meaning all of the information it uses to produce its responses is frozen in 2021. Also, much of Lenny’s writing is behind a paywall. That means that even though GPT-3 has read the whole internet, it won’t have the material from his newsletter available to construct answers.
So how could we construct a chatbot with GPT-3 that solves these problems? Ideally we want to feed GPT-3 the information it needs to answer questions spontaneously. That way it will have the right information available and be less likely to make things up.
There’s an easy way to do that.
Stuffing context into the prompt
When I was in high school, I had a physics teacher who allowed open-book tests. He would allow you to bring a single index card to the test with any of the formulas that you thought you needed to answer the questions.
Memorizing the formulas didn’t matter so much, but what did was using your reasoning abilities to turn the formulas into the correct answer.
People would come to the test with microscopic handwriting covering every inch of their notecard, which was a helpful strategy. The formulas gave you the context you needed to think through the answers to the questions on the tests, so the tests became less about your memory and more about how well you understood the topic. (I got a B in that class, so my understanding was pretty average.)
You can work with GPT-3 in a similar way. If, in your prompt, you include the equivalent of a notecard with context to help it answer the question, it will often get it right. (Its reasoning capabilities are better than mine.)
Let’s go back to an example GPT-3 failed on earlier and see if we can correct it with this technique.
As I mentioned above, in his post on consumer businesses, Lenny notes that less than a third of the founders got their idea from trying to solve their own problem:


Let’s ask GPT-3 this question again—but with a little help. We’ll feed it the equivalent of a notecard that has written on it the section of Lenny’s article with the answer. Then we’ll see if it can get it right.
To make this fair, we won’t give it just the text containing the answer. We’ll give it some of the surrounding text in the article as well to see how it does. Let’s see if it works:

But this introduces another problem: space limitations.
The notecard analogy is apt because there’s limited space in the prompt—right now, about 4,000 tokens (each token is the equivalent of three-quarters of a word). So we can’t feed in Lenny’s entire archive on every question. We have to be choosy about what we select.
Let’s talk about how to solve this.
Embedding Lenny’s archive
At this point we’re going to have to move out of manual interactions with GPT-3’s Playground and start using chunks of code that work directly with the GPT-3 API. The code we’re building is going to do the following tasks:
- We need to download and store Lenny’s archive in a way that makes it easily searchable for our bot.
- We need some code that will help find relevant chunks of text from the archive of Lenny’s content that we created in the previous step.
- When a user asks a question, we want to use the code from the last step to get the chunks of text that are most likely to answer the question, and put them into the prompt that we send to GPT-3.
- We’ll display the resulting answer to the user.
This is simple to do with a library called GPT Index, an open-source library created by Jerry Liu. It’s separate from OpenAI but built to help with tasks like this. Here’s how it works:
- Create an index of article chunks.
- Find the most relevant chunks.
- Ask our question to GPT-3 using the most relevant chunk.
Note: This is about to get a little bit more complicated and technical. If you’re interested in that, read on for an explanation.
You can access and run the code from this article in a Google Colab file. Colab is a cloud-based programming environment that will let you run everything from your browser. (If you have questions about any of this, reach out to me on Twitter.)
If you’re not interested in the technical details, skip to the end to try out the chatbot for yourself.
Still here? Great. Let’s start with index construction.
Constructing our index
The first thing we need to do is construct our index. You can think of an index as a database: it stores a collection of pieces of text in a way that makes them easily searchable.
First we collect Lenny’s newsletter archive into a folder. Then we ask GPT Index to take all of the files in the folder and break each one into small, sequential pieces. Then we store those pieces in a searchable format.
The code looks like this:
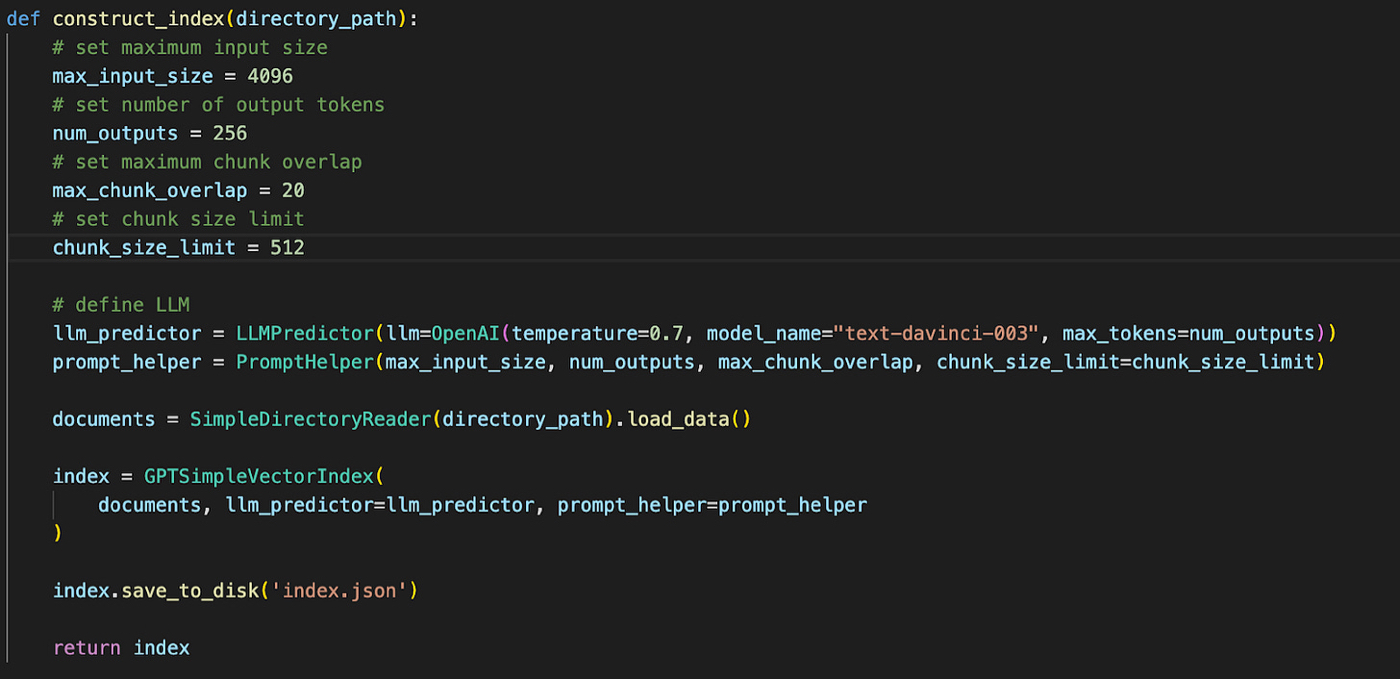
Embeddings are handy because when a user asks a question, they’ll make it easy to search Lenny’s archive and find articles that are most likely to answer our question.
With that in mind, let’s run the code and see what happens.
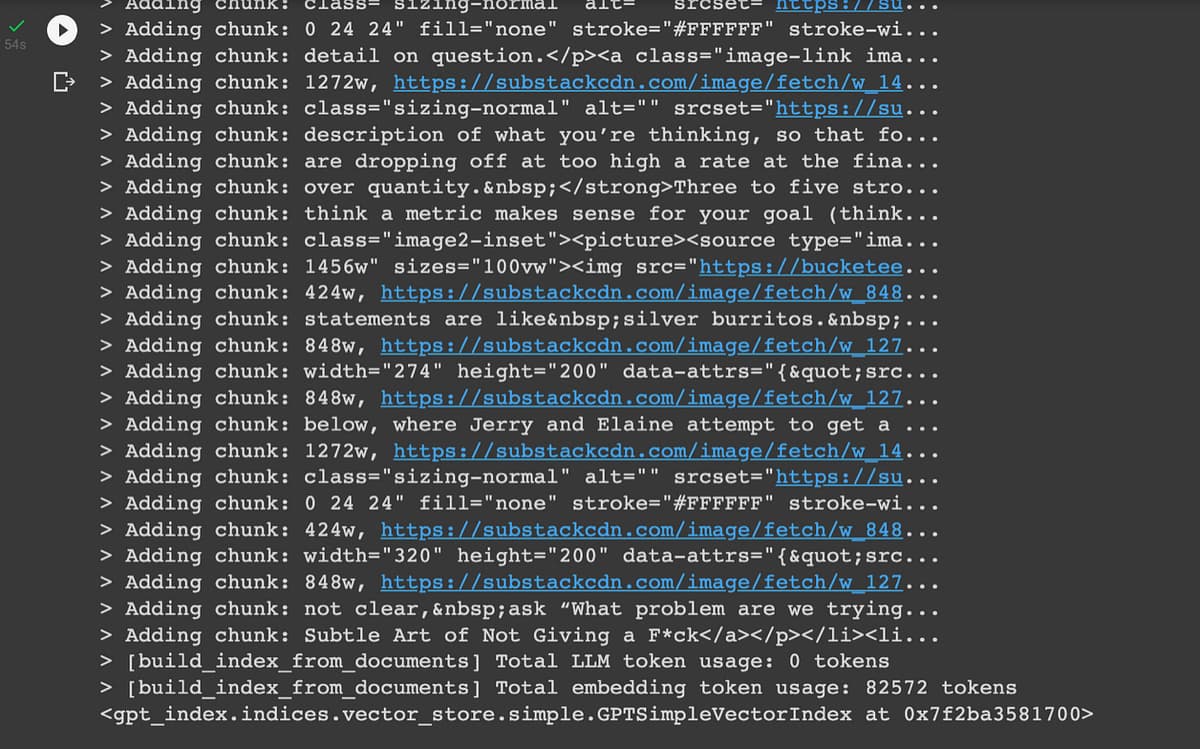 Success! The Lenny’s archive is fully indexed, and we can query it to find relevant chunks of documents and use those chunks to answer our questions. (Be careful if you do this with big documents, as embeddings cost $0.0004 for every 1,000 tokens.)Asking our question
Success! The Lenny’s archive is fully indexed, and we can query it to find relevant chunks of documents and use those chunks to answer our questions. (Be careful if you do this with big documents, as embeddings cost $0.0004 for every 1,000 tokens.)Asking our question
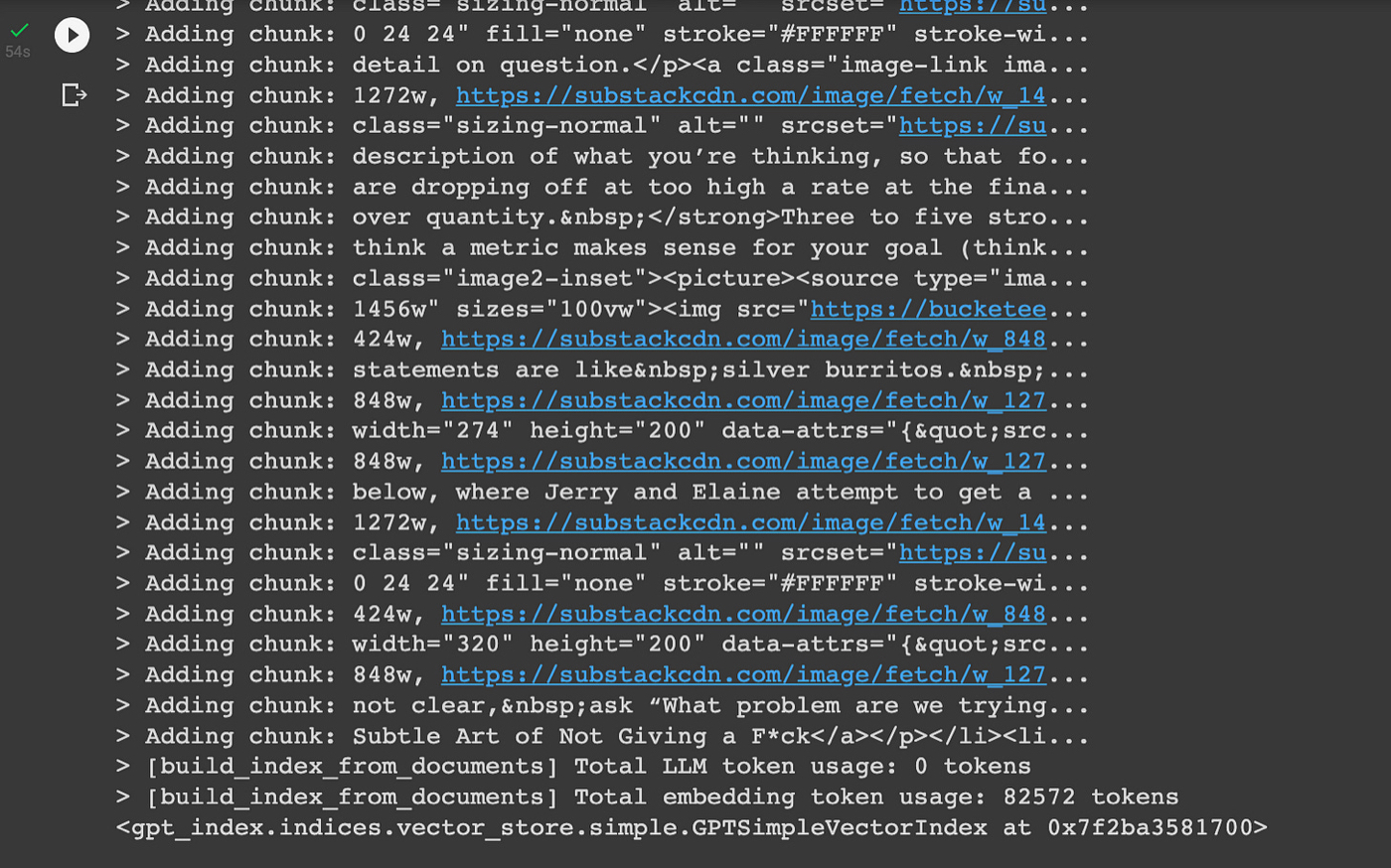
To query the index we created in the last section, all we have to do is paste a question into GPT Index. It will then:
- Find the chunks of our index that are most relevant to the question.
- Combine those chunks and our question into a prompt that it sends to GPT-3.
- Print the output.
Here’s what the code looks like:
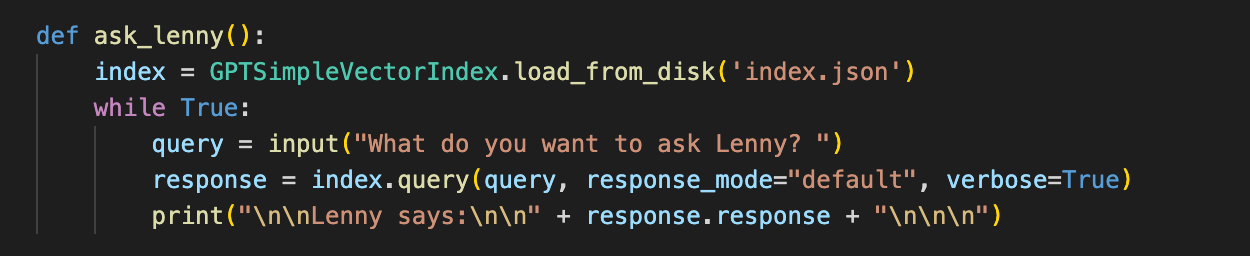
“25% is good.”
If I query it, “Is it best for consumer startup ideas to come from founders who are trying to solve their own problem?” it returns the right answer:
“Based on the research, it appears that it is a good idea for consumer startup ideas to come from founders who are trying to solve their own problem, as this was the strategy used by around 30% of the most successful consumer companies.
However, it is not necessarily the best strategy, as other strategies such as paying attention to curiosity, what’s already working, and paradigm shifts were also used by a significant number of successful companies.”
We now have an end-to-end solution to turn questions into answers that are based on Lenny’s archive. And it only took a few lines of code!
If you want to see the results in action, check out the bot:
You can also access the full source code for this article in this Colab notebook. More details exclusively for Every subscribers are at the bottom of this post.What all of this means
This is just the beginning. The horizon of possibility is shifting almost every day with these technologies. What’s hard to do today will be easy in a matter of months.
Every newsletter, book, blog, and podcast that’s used as evergreen reference information by its audience can now be repackaged as a chatbot.
This is great for audiences because it means that any time you want to know what Lenny (or any other creator) says about a topic, you’re not going to have to sort through an archive of articles or podcast episodes in order to get their answer to your question. Instead, you’ll just be able to use Lenny’s chatbot to get his answer instantly—and then maybe later read the article in full if you want more details.
This is also great for content creators. They now get the ability to monetize the content they’ve already created in new ways, and lessen the amount of repetitive questions they have to answer. This will (hopefully) give them more time and money to create great content.
A new class of content creators will learn to create compelling chatbot experiences that combine their personality and worldview for their niche audience in the same way that some creators learned to create compelling YouTube videos, newsletter articles, or TikTok clips.
If you use Lenny’s chatbot or follow the code samples, you’ll see that it’s promising but not yet perfect. There are tremendous returns available to the individuals or groups who learn to make these types of experiences incredible for users.
I hope this inspires you to embark on that journey.
More details for Every subscribers
In this section, I’ll give an update for Every paying subscribers on:
- How launch day went
- Server-side code samples
- Client-side code samples including React code and CSS
Let’s dive in!
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
















