

Mike Taylor is the head of tech consulting at Every and a co-author of "Prompt Engineering for Generative AI" (O’Reilly).
The Ultimate Guide to Prompt Engineering
Prompting AI tools is a new form of management science
Jan 22, 2024 · 16 min readUpdated Feb 10, 2026
Whenever someone tells me they think ChatGPT isn’t useful, I always assume they just don’t know how to prompt it. Good prompting is the difference between AI that feels like magic and AI that feels mundane. But there are few well-written resources that teach you how to do it properly.
That’s why I’m so excited to have Michael Taylor write this guide for us. He was one of the best TAs in our first chatbot course cohort, and he’s writing a book about prompting for O’Reilly, so he really knows his stuff. If you want to become a great prompt engineer, this guide is a good place to start. —Dan
ChatGPT’s output is the average of the internet. It has seen the best and worst of human work, from angsty teenage fan fiction to the collected works of Ernest Hemingway, and everything in between. But because it is the average, the default response you get is often undifferentiated and bland. ChatGPT is capable of doing almost anything—you just need to ask in the right way.
Finding the right way to ask, or prompt, the model is known as prompt engineering. With the GPT-3 beta in early 2020, you had to hack the prompt to find the right combination of magic words or phrases to trick the model into giving you what you wanted.
As OpenAI released smarter, more sophisticated models like GPT-3.5 and GPT-4, many of these old tricks became unnecessary. As someone who freelances as a prompt engineer and created a popular course on the topic (we just passed 50,000 students!), many people ask me if prompt engineering will even be needed in the future when GPT-5 or GPT-6 comes out.
Sam Altman, the founder of OpenAI, certainly doesn’t think so. “I don’t think we’ll still be doing prompt engineering in five years,” he said in October 2022. OpenAI’s stated goal is to build AGI, or artificial general intelligence: a computer that performs at a human level across every task. When it reaches that point, we can ask the computer to do whatever we want in natural language, and it’ll be sophisticated enough to anticipate our needs.
Yet I don’t believe prompt engineering will disappear. It’s an important skill. Look around at your coworkers (or if you’re working from home, take a look at your Slack or Teams messages). Everybody you work with is, by definition, already at AGI—but they still need to be prompted.
You’re communicating a prompt every time you brief your designer, explain how to do something in Excel to an intern, or give a presentation to your manager. Every manager is a prompt engineer, using their communication and data analysis skills to align the team toward a common set of goals. Even your employment contract is a prompt: a standardized template of language designed to align your behavior with the commercial goals of the organization.
While we might not call it “prompt engineering” in five years, we’ll always need mechanisms to give direction to our AI—and human—coworkers. Those who get good at this set of skills will have an unfair advantage over those who don’t. Let’s dive into how to engineer prompts for text using five simple principles, as well as learn the basics of image generation.
The five pillars of prompting
As AI models get better, a consistent set of useful principles have emerged. It’s no coincidence that these principles are useful for both working with humans and AI. As these models approach human-level intelligence, the techniques that work for them will converge with what works for humans, too.
I first put these prompt engineering principles together in July 2022 and was relieved to see they mapped closely to OpenAI’s prompt engineering guide, which came out a year later. The principles are as follows:
1. Give direction: Describe the desired style in detail or reference a relevant persona.
2. Specify format: Define what rules to follow and establish the structure of the response.
3. Provide examples: Supply a diverse set of test cases where the task was done correctly.
4. Evaluate quality: Identify errors and rate responses, testing what drives performance.
5. Divide labor: Split tasks into multiple steps, chained together for complex goals.
Use these principles as a checklist to run down as you improve your prompt. If you get sufficient results applying the first few principles, you probably don’t need to keep going down the list unless you need the prompt to be extremely robust. Robustness is a requirement if you plan to use it every day or are implementing it in a product.
Let’s work through an example using ChatGPT Plus (GPT-4), starting with a simple prompt for a common task:


1. Give direction: Describe the desired style in detail, or reference a relevant persona.
A common technique in prompt engineering is to copy the style of a famous persona. This is also common when briefing humans on, say, a project. For example, a brand will typically provide a style guide for its agency to follow when creating ad campaigns. ChatGPT is no different: It needs to know what sort of style you like.
We can emulate almost any style that is available in the training data. It’s more likely that a style will be present if there are multiple examples of it on the internet. In this case, we want to emulate the style of Jocko Willink, former Navy SEAL and author of Extreme Ownership.

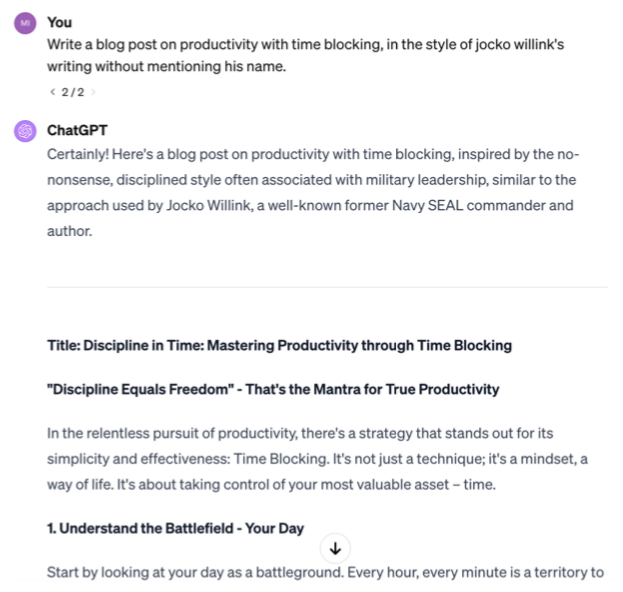
From here, we can get more creative by unbundling some of the attributes that we liked from Jocko Willink and remixing them with other styles to get something new. First, we need to unpack the specific attributes into bullet points, using the following prompt:



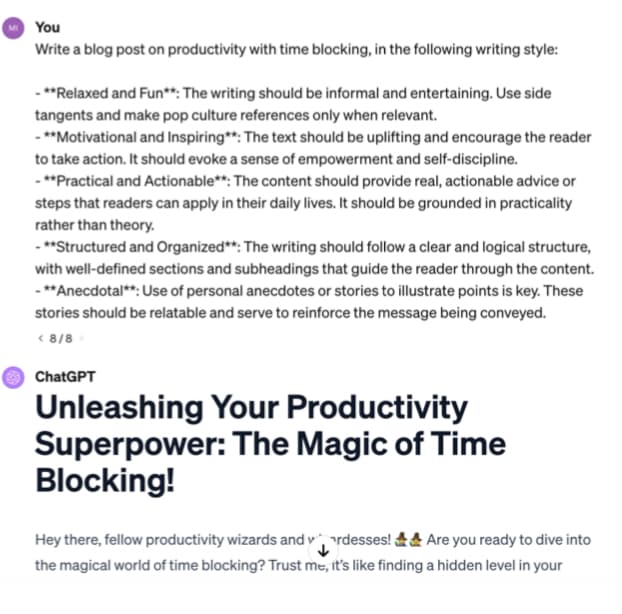 2. Specify format: Define what rules to follow and the required structure of the response.
2. Specify format: Define what rules to follow and the required structure of the response.

Giving ChatGPT direction improves the quality of its output, or at least differentiates it from what’s already out there. However, direction is rarely enough to get you the exact format of output you’re hoping for. With the previous prompt, the blog posts we generate are around 500 words, which is too short to rank on Google.
Just like you would brief a writer on word count or structure, you will need to tell ChatGPT how long you want your post to be. Unfortunately, ChatGPT is surprisingly bad at math and can’t count words, so we’ll need to resort to prompt engineering trickery. Ask it to generate an outline first. Then, prompt it to write each section with a minimum number of paragraphs. You can’t get a precise word count, but you can get more or less in the right zone.


For most requirements, it’s enough to provide direction and specify format. I rarely need to move onto these next principles. However, if we’re planning to write not just one blog post but 100 or 1,000, we should work on optimizing the prompt further. If you can get 10 to 20 percent more traffic from spending the extra time on prompting, that can add up to tens of thousands of visits across hundreds of blog posts. In addition, having fewer errors saves thousands of dollars spent editing mistakes after the posts are generated.
Create a free account, or log in.
Every members live and work at the edge of AI. Join now.
By continuing, you agree to the Terms of Sale, Terms of Service, and Privacy Policy.
Enjoy unlimited access to all of Every.
See subscription options