

Mike Taylor is the head of tech consulting at Every and a co-author of "Prompt Engineering for Generative AI" (O’Reilly).
How to Grade AI (And Why You Should)
Evals are often all you need
Mar 11, 2024 · 11 min readUpdated Dec 17, 2025
AI isn’t like other software. Historically, when you used a computer, input X would always give you output Y. With AI, you give it input X and get back output I, T, D, E, P, E, N, D, S. The computer responds with a marginally different answer every time, so evaluating and comparing these tools is a devilishly hard task. But because we are devoting ever more of our intellectual effort to LLMs, this is a task we must figure out. Michael Taylor has spent an obscene amount of time trying to build AI evaluations, and in this article, he tells how you can do the same. As go the evals, so goes the world. —Evan Armstrong
To paraphrase Picasso, when AI experts get together, they talk about transformers and GPUs and AI safety. When prompt engineers get together, they talk about how to run cheap evals.Evals, short for “evaluation metrics,” are how we measure alignment between AI responses and business goals, as well as the accuracy, reliability, and quality of AI responses. In turn, these evals are matched against generally accepted benchmarks developed by research organizations or noted in scientific papers. Benchmarks often have obscure names, like MMLU, HumanEval, or DROP. Together, evals and benchmarks help discern a model’s quality and its progress from previous models. Below is an example for Anthropic’s new model, Claude 3.
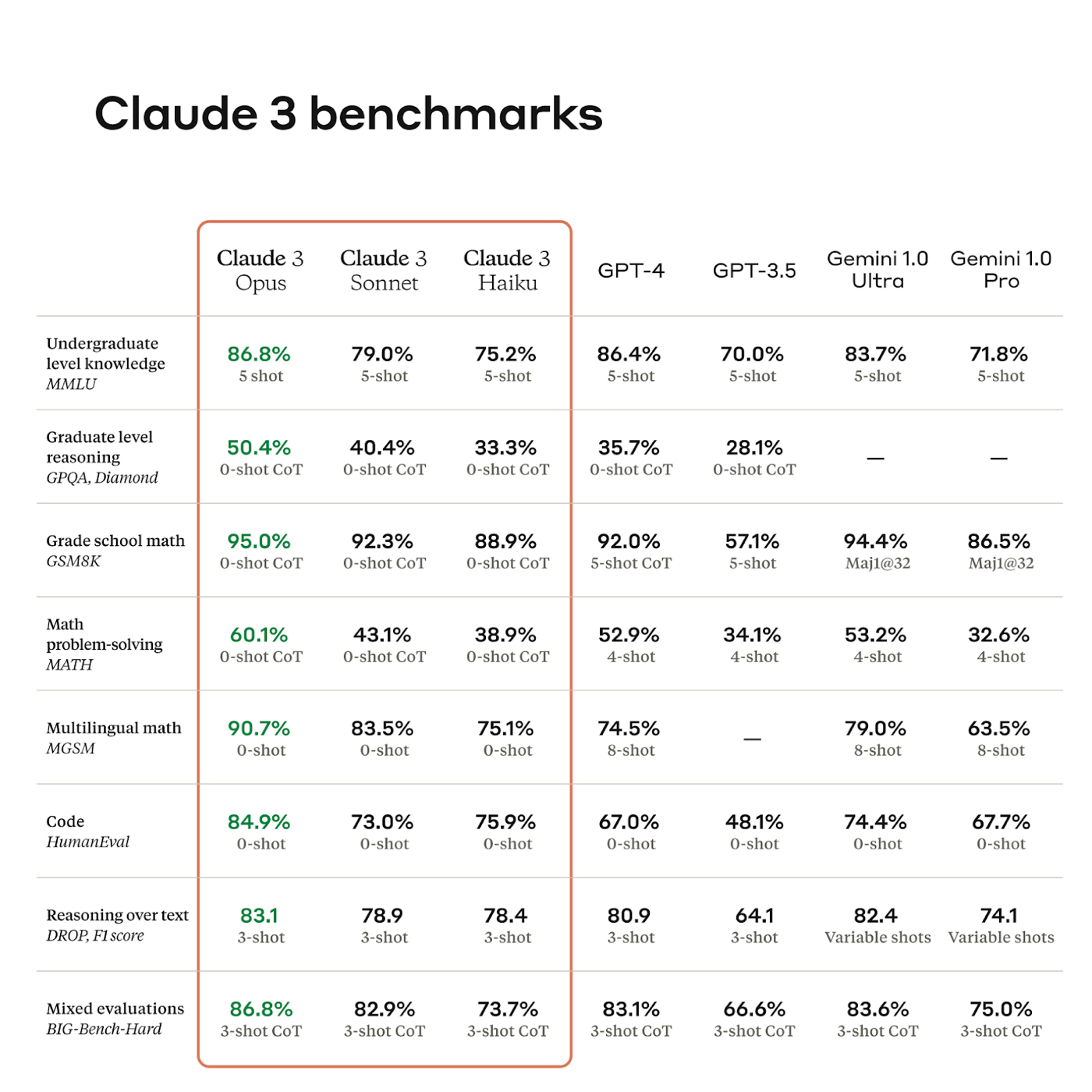
Source: Anthropic.
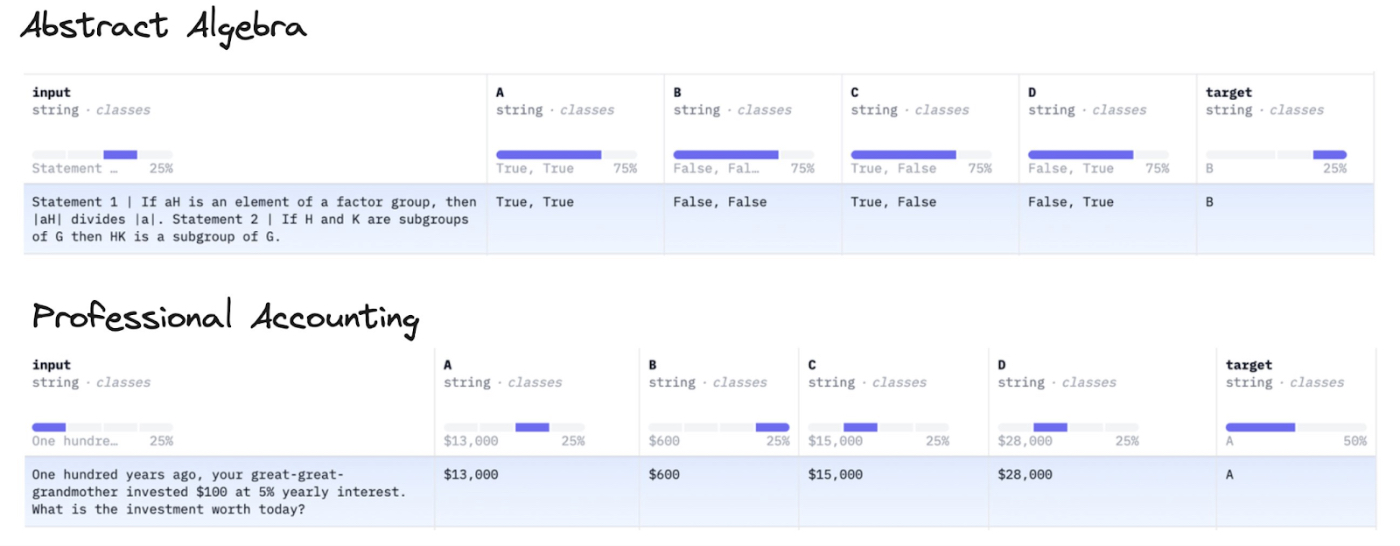
Benchmarks are lists of questions and answers that test for general signs of intelligence, such as reasoning ability, grade school math, or coding ability. It’s a big deal when a model surpasses a state-of-the-art benchmark, which might enable its company to attract key talent and millions of dollars in venture capital investment. However, benchmarks are not enough. While they help researchers understand which models are good at tasks, the operators who are using these models don’t depend as much on them: There are rumors that answers to benchmark questions have “leaked” into the AI models’ training data, which makes them subject to being gamed, or overfit to the data in undefined ways.
And even though head-to-head comparison rankings—where the results of two models for the same prompt are reviewed side-by-side—use real humans and can therefore be better, they’re not infallible. With Google Gemini able to search the web, it’s like we’re giving the AI model an open-book exam.
As OpenAI cofounder and president Greg Brockman puts it, “evals are surprisingly often all you need.” Benchmarking can tell you which models are worth trying, but there’s no substitute for evals. If you’re a practitioner, it doesn’t matter whether the AI can pass the bar exam or qualify as a CFA, as benchmarks tend to discern. Evaluations can’t capture how it feels to talk to a model. What matters is if they work for you.
Source: X/Greg Brockman.
In my experience as a prompt engineer, 80–90 percent of my work involves building evals, testing new ones, and trying to beat previous benchmarks. Evals are so important that OpenAI open-sourced its eval framework to encourage third-party contributions to its question-and-answer test sets to make them more diverse.
In this piece, we’ll explore how to get started with evals. We’ll touch on what makes evals so hard to implement, then run through the strengths and weaknesses of the three main types of eval metrics—programmatic, synthetic, and human. I’ll also give examples of recent projects I’ve worked on, so you can get a sense of how this work is done.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.













