

Nir Zicherman is the cofounder and CEO of Oboe. Previously, he cofounded of Anchor and was the vice president of audiobooks at Spotify.
How AI Works
An entirely non-technical explanation of LLMs
Jan 29, 2024 · 9 min readUpdated Jul 14, 2026
One secret about the world is that most big ideas aren’t that complicated. If they’re explained properly, you’ll see that even things that seem impenetrable—like AI—operate on simple principles that almost anyone can understand. That’s what I love about this piece by Nir Zicherman: It will build your intuition for how this current generation of AI works, in simple and intelligble language. I hope it feeds your curiosity. —Dan
For all the talk about AI lately—its implications, the ethical quandaries it raises, the pros and cons of its adoption—little of the discussion among my non-technical friends touches on how any of this stuff works. The concepts seem daunting from the outside, the idea of grasping how large language models (LLMs) function seemingly insurmountable.
But it’s not. Anyone can understand it. And that’s because the underlying principle driving the surge in AI is fairly simple.
Over the years, while running Anchor, leading audiobooks at Spotify, and writing my weekly newsletter, I’ve had to find ways to distill complicated technical concepts for non-technical audiences. So bear with me as I’ll explain—without a single technical word or mathematical equation—how LLMs actually work. To do so, I’ll use a topic we all know well: food. In the analogy to LLM, “dishes” are words and “meals” are sentences. Let’s dive in.
The menu
Imagine this: You’re cooking a dinner, but you need to come up with one more side dish. The food you’re preparing is just shy of being enough. So we need one more component to add to the meal.
But that’s easier said than done. What we pick needs to fit in with the meal. If the meal is savory, our side dish needs to be, too. If it already has a salad, we shouldn’t make another. If the meal is starch-heavy, maybe we want to throw in a roasted vegetable.
Wouldn’t it be nice to have an app that just tells you what to make? One that considers what you’re already making and comes up with the optimal side dish? This app should work for any meal, with any combination of dishes and flavors, regardless of whether it’s feeding four people or 40.

All illustrations by the author. Images generated by ChatGPT.
We’re going to make this app. It will only take two simple steps.
First, we’re going to have it develop a method for categorizing foods. After all, computers don’t have taste buds, nor do they have an intuitive understanding of food or how flavors fit together. They need to be able to take the novel concept of food and encode it as some kind of data.
Second, we’re going to have the app learn how to take an existing set of dishes and spit out new ones. It’s not merely going to memorize what it’s seen before. Recall that this app needs to work for any combination of dishes, even ones it’s never seen paired together. So we’re not just going to program the system. We’re going to teach it.
Step one: modeling meals
We’ll start by teaching the computer to think about meals as data. We’re not going to do this by providing it with qualitative details about the meal, like what it tastes like or what it fits with. That’s the old type of machine learning—too limiting and error-prone. Instead, we’re going to feed it a lot of data about the types of dishes people have paired together in the past.
Let’s consider two types of dishes: a caesar salad and a caprese salad. We, as humans, know that these two dishes are similar. They’re both Italian, they’re both salads, they both contain vegetables and cheeses…but a machine need not know any of the above to learn how similar these two dishes are.

It’s highly likely that caesar salads are often paired with other Italian dishes within our mountain of data. And it’s also likely that the presence of a ceasar salad means that there won’t be another salad in the meal. The same can be said of caprese salads. They won’t typically appear with other salads, but they will appear with Italian dishes.
Because these two dishes will often co-occur with the same types of dishes, we can categorize them as being similar. They tend to be found in the same patterns of food. You might say “a dish is characterized by the company it keeps.”
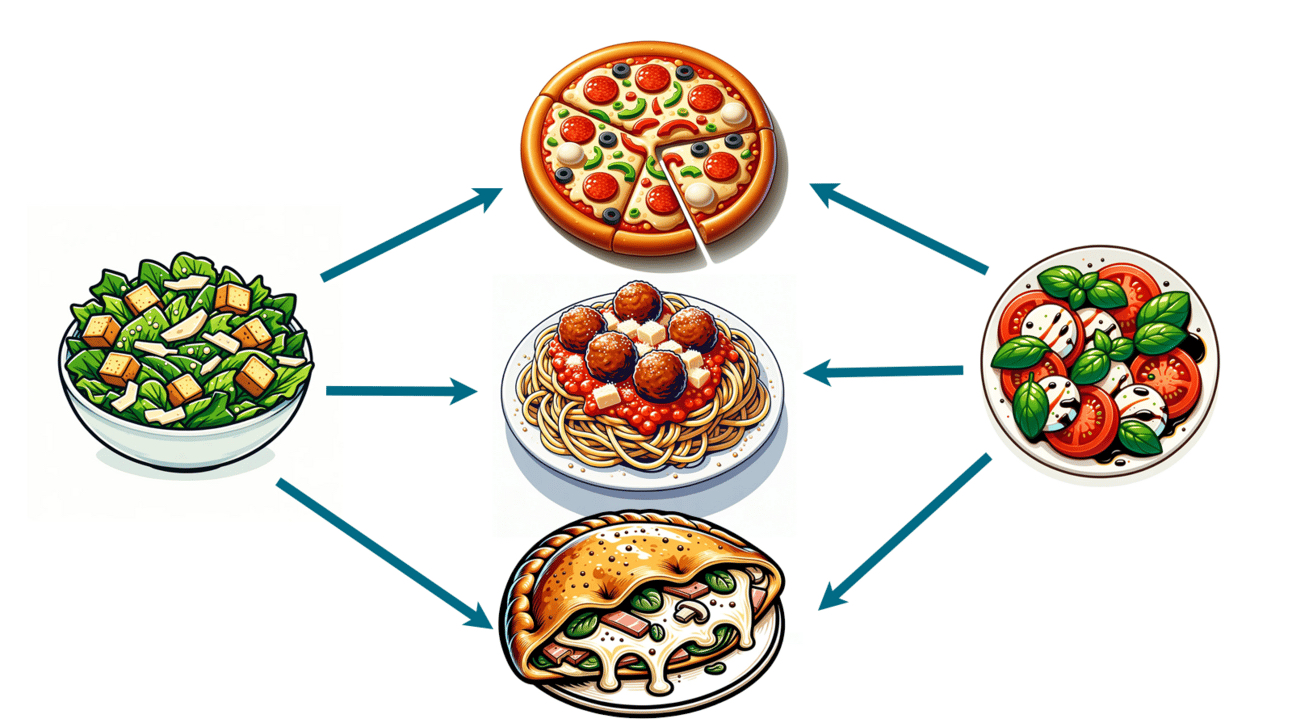
Notice that we didn’t look for any meals in which caesar and caprese salads occur together. They never need to occur together for us to deem the dishes similar. They simply need to be found among the same other dishes.
Here’s another way to think about what we just did. Imagine we wanted to graph all dishes on this chart:
To start, we took all the possible dishes we found in our data and plotted them randomly:
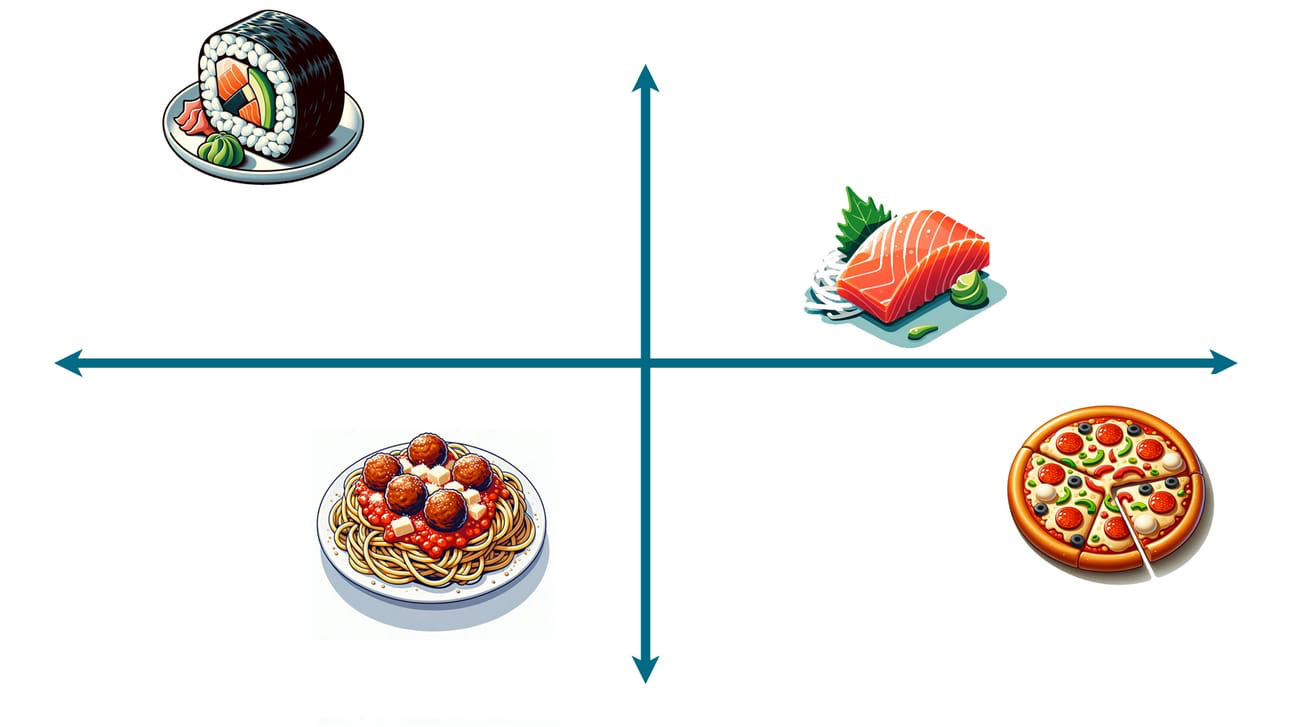
We’re only showing four dishes here for illustrative purposes, but imagine literally every possible dish.
Each time we find two foods that co-occur with other dishes, we can move them closer together. As we see different types of sushi coupled with the same miso soup, we’re going to inch the sushi toward each other. As we see pizza and spaghetti appear alongside garlic bread, we’ll let them come together too:
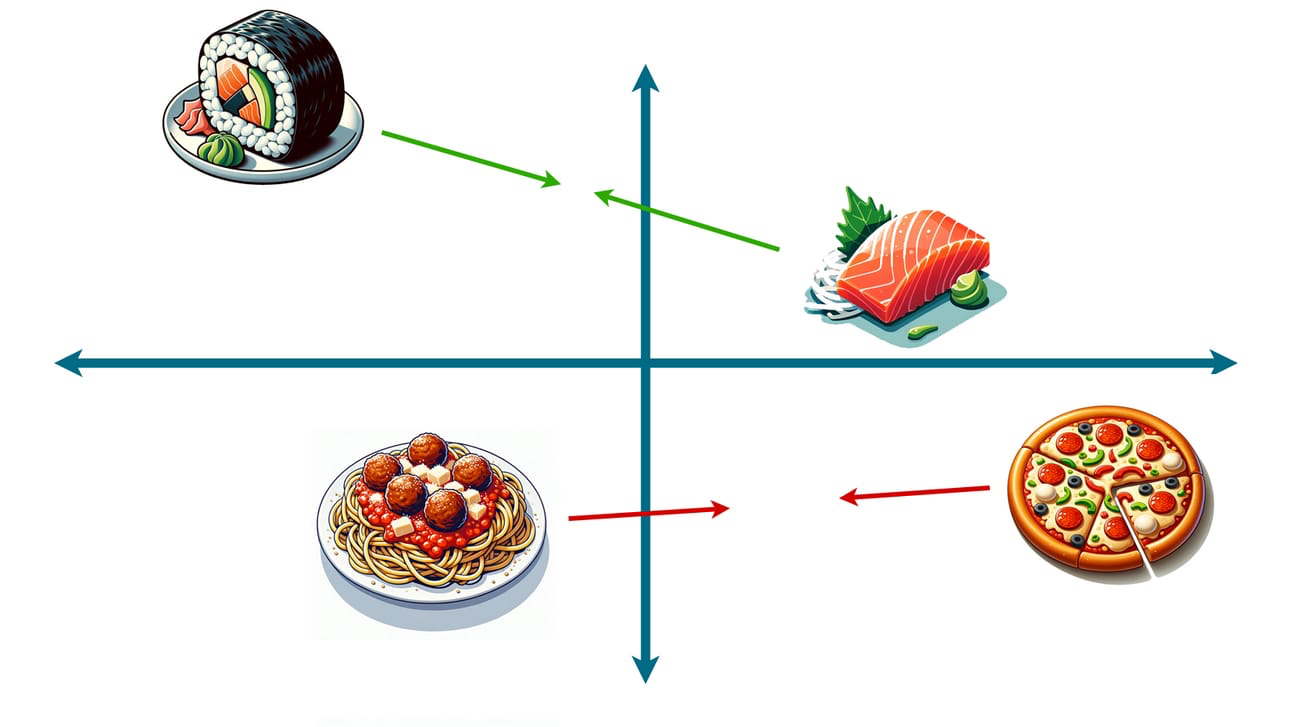
And after doing this many times (and I mean many times), something magical occurs. Dishes that are interchangeable will cluster very closely together. Dishes that are somewhat interchangeable (say, tacos and burritos) will appear closer to each other. And dishes that are rarely—if ever—interchangeable (say, burgers and sushi) will be placed far apart.

Now, in practice, two dimensions aren’t enough. To truly cluster every dish appropriately, we would need a graph consisting of many more axes (hundreds, maybe thousands). That’s impossible to visualize, but the underlying concept is the same. We scatter all our foods and move them closer as they co-occur with similar dishes.
As a shorthand, I’m going to refer to this larger multi-axis graph as meal-space. Every possible dish exists in meal-space, sitting at close coordinates with interchangeable dishes and far from those that are very different.
Let’s take a step back and appreciate how fascinating this is. We were able to come up with a very accurate model of dishes, wherein similar ones are grouped together and different ones are far apart. And we did it without factoring in anything about how the foods taste or what they’re made of.
Plus, because we trained this on so much data, we’re able to do food arithmetic.
Food arithmetic? “Nir, you’re crazy!”
I assure you, I’m not. You’ll have to take my word for it, but it turns out that the placement of dishes in our meal-space isn’t random. In fact, not only are similar meals spaced together, they also share logical relationships with other food. Dishes containing bread all appear on one plane together. Salty foods lie on a common line. Maple-flavored things have their own mathematical link.
And that allows us to do food arithmetic. If I were to take the coordinates for a burrito and subtract the coordinates for a tortilla, I’d end up near the point of a burrito bowl. If I were to take the coordinates for chicken noodle soup, subtract the coordinates for noodles, and add the coordinates for rice, I’d end up near the point for chicken and rice soup.
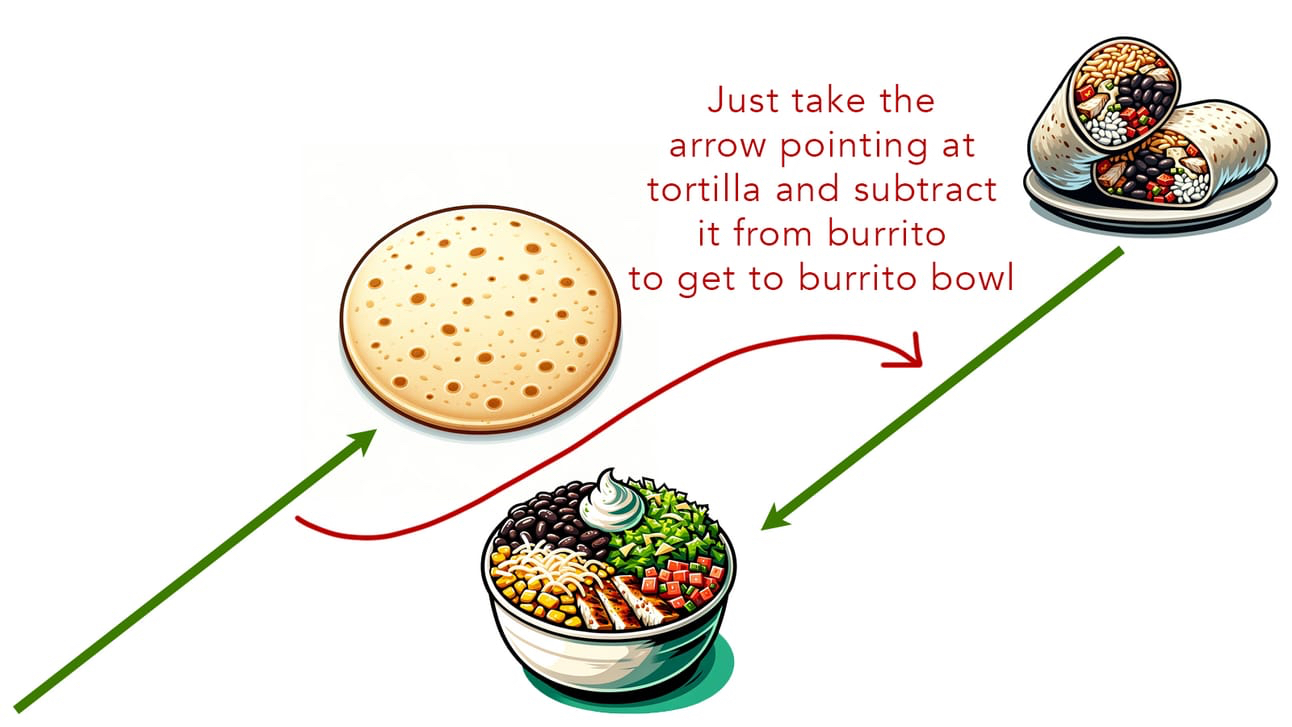
The placement of dishes in meal-space isn’t random anymore. In fact, there are underlying, hidden mathematical patterns that mean every food is placed in some logic relative to every other food.
Step two: finding patterns
We’ve created a meal-space and given every type of dish some kind of coordinate that makes sense relative to every other dish. Now what?
Well, let’s train our model again. Only this time, we’ll feed it whole meals, made up of component dishes—we’re talking about every meal we’ve ever seen—and we’ll ask it to find patterns. Specifically, we want to train our program to answer this question: If a meal contains A, B, C, and an unknown D, what type of dish is most likely to be D?
And to do that, all we have to do is ask: What do A, B, C, and the unknown D look like in meal-space? For instance, let’s say we see many meals that share dishes in these four areas of the graph.

We can now generalize and think solely about coordinates in meal-space, ignoring the original foods that created these patterns in the first place. We can conclude that if a meal already contains dishes in these three regions, the best fourth component would be found in that last region.
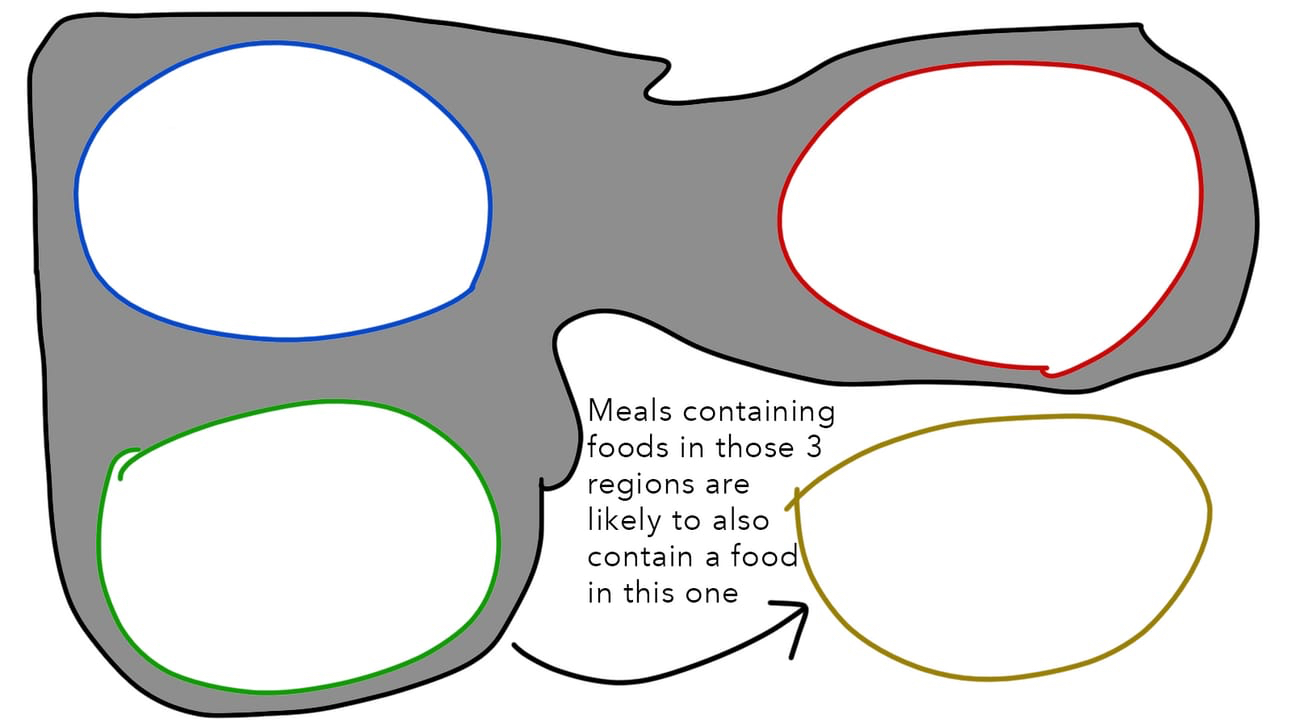
Remember: “A dish is categorized by the company it keeps.” And because our model was trained to think about foods and their relationships, rather than the ingredients and tastes of specific dishes, it can take any scenario and any combination of flavors and figure out the most optimal dish to add to the meal. Given a few regions of food, it just needs to find the most common region the next dish would be in…
…which takes us back to our original goal, now completed. We wanted to build an app that could reliably tell us which dishes to pair with a selection of other dishes. And we did just that.
Words instead of recipes
To understand LLMs, replace the concept of meals with sentences. And replace the concept of dishes in those meals with words. That simple substitution, with the same framing and approach, essentially gets you to the gist of how generative text-based AI tools work.
Step one: Train a model to understand the relationships between words based on how often they appear in similar contexts. “A word is categorized by the company it keeps.” Feed it a ton of human-written data (and when I say a ton, I essentially mean the entire internet), and let it nudge word coordinates around appropriately.
The output isn’t called meal-space anymore. It’s called vector-space. But the principles are the same. The system has no awareness of what any word means (just like it had no awareness of how a dish tastes). It only understands how that word is related to every other word in vector-space.
Step two: Find patterns. If a sentence contains words A, B, and C, what’s the next most likely word to appear? If it contains X and Y, what region of vector space should it look in for what comes next?
In the case of LLMs, all they’re really doing under the hood is what’s referred to as “next word prediction" (just as our original analogy performed “next dish prediction”). For instance, let’s say you prompted an LLM with: “Tell me you love me.” It would attempt to answer one question: What word is most likely to follow that sequence of words? Or phrased differently: Given the vector-space coordinates of the words in that sentence, what patterns have I seen in other sentences to determine where I can find the next word?
The answer the LLM will find is “I.” And having determined that, it will tack the “I” to the end of your original prompt and feed that whole thing back into itself. Now, what word is most likely to come next after “Tell me you love me. I”? Why, “love,” of course! Tack it on, take the whole thing, and feed it back in. What’s likely to come next: “Tell me you love me. I love”?…
You get the idea.
Of course, there’s a bit more nuance. There’s some fancy math and complex computing involved. But the fundamentals truly are no different than those in the meal-planning example.
To me, this is why the AI phenomenon we’re living through is so fascinating. Considering how transformative this technology is, it’s not actually that complicated. A few simple mathematical concepts, a whole lot of training data, a sprinkle of salt and pepper, and you’ve essentially built yourself a thinking machine.
Nir Zicherman is a writer and entrepreneur. He was the cofounder of Anchor and the vice president of audiobooks at Spotify. He also writes the free weekly newsletter Z-Axis, in which this article was originally published.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.














Comments
Don't have an account? Sign up!